Vision AI Pipelines
Object Detection
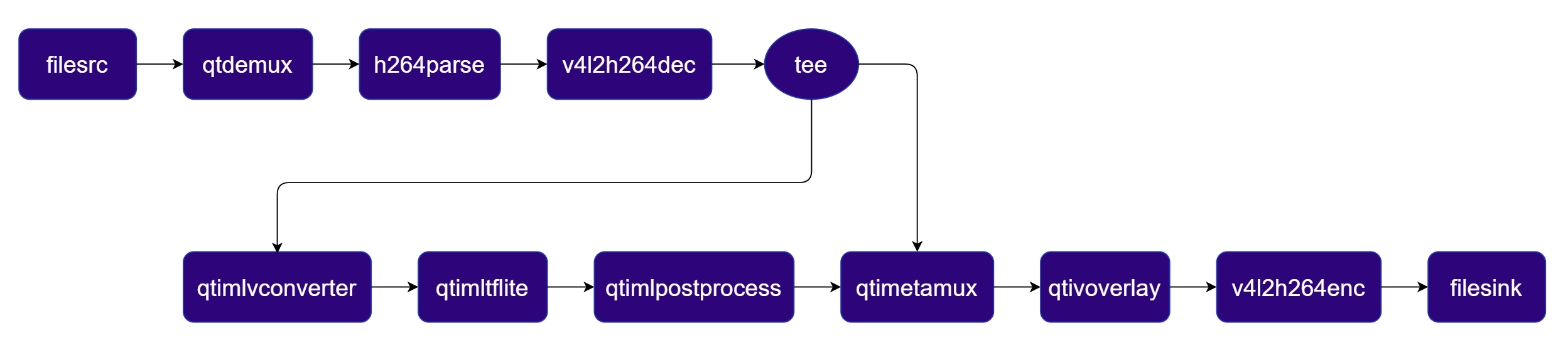
Single‑Stream Object Detection Pipeline.
Detects objects in each frame using a YOLOX LiteRT model and overlays bounding boxes and labels. Pipeline Diagram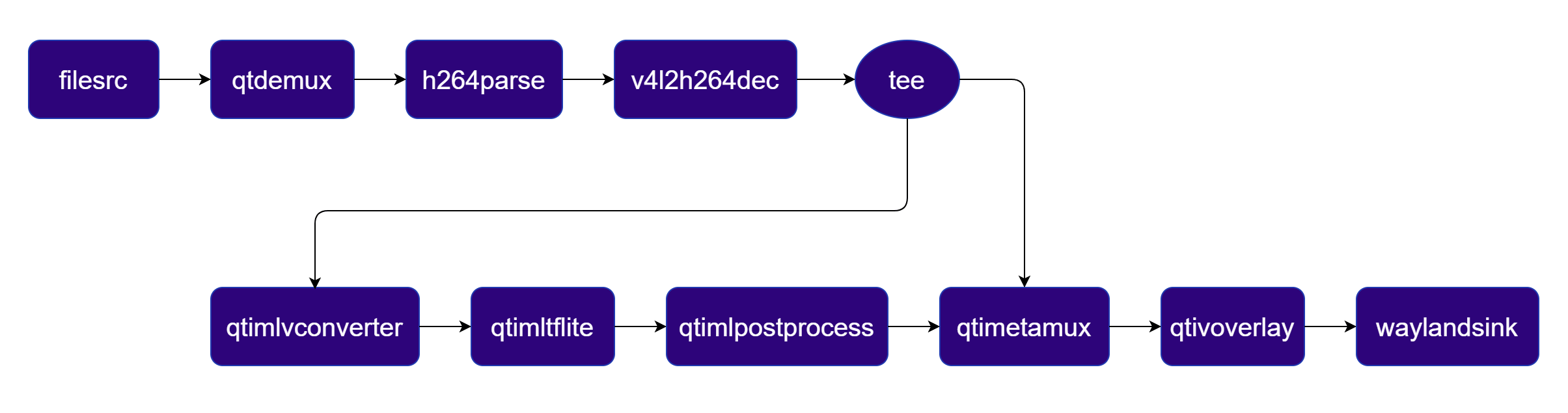
Try me
Try me
Download Required Files:
| File | Download | Save as |
|---|---|---|
| YOLOX W8A8 model | Qualcomm AI Hub — YOLOX | yolox_w8a8.tflite |
| Detection labels | yolov8.json | yolov8.json |
| Sample video | Input video | ai_demo_sample.mp4 |
.zip archive, extract it on your host machine before copying:
unzip filename.zipCopy files to device

Input:- filesrc
Input:- filesrc
Input:- USB Camera(v4l2src)
Input:- USB Camera(v4l2src)
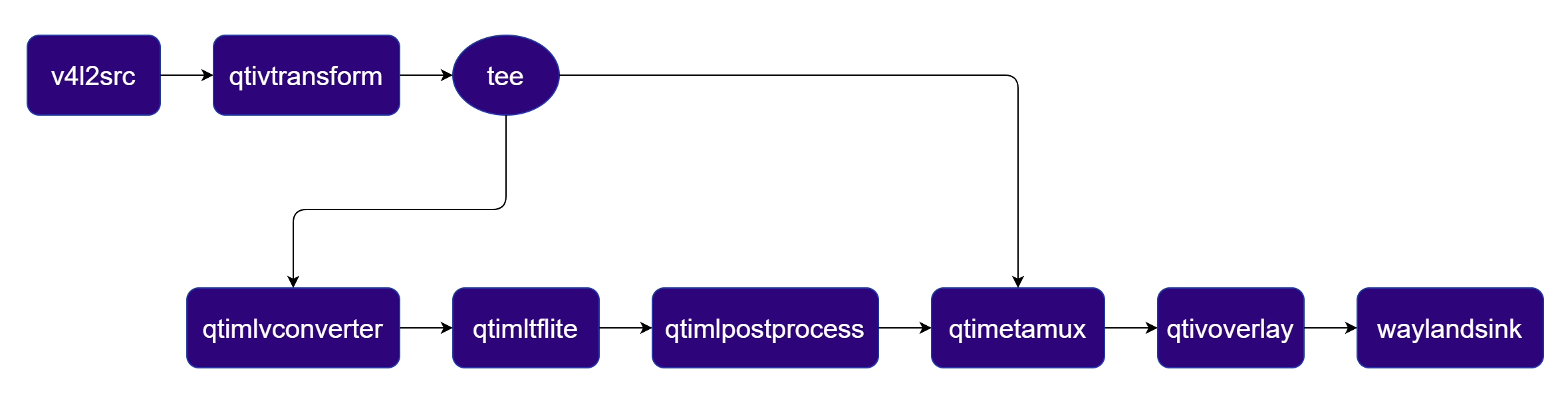
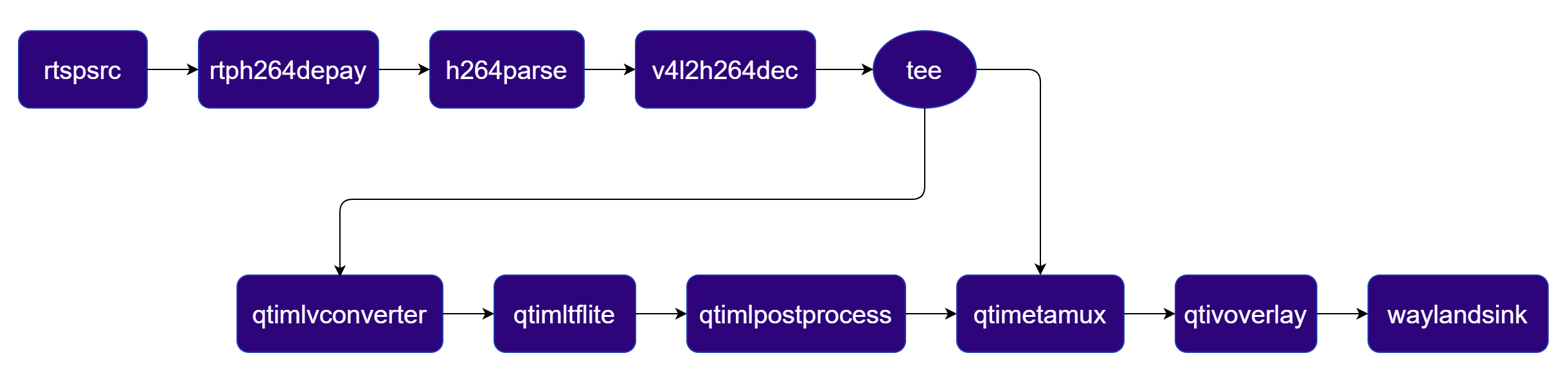
Input:- RTSP(rtspsrc)
Input:- RTSP(rtspsrc)
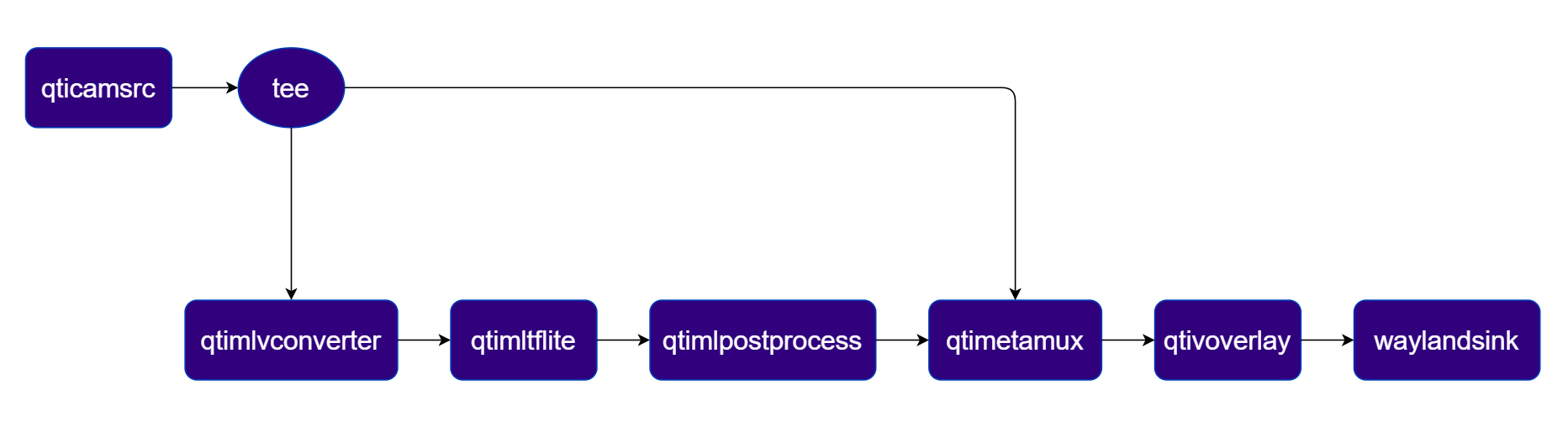
Input:- ISP Camera (qticamsrc)
Input:- ISP Camera (qticamsrc)
Input:- filesrc
Input:- filesrc
Input:- USB Camera(v4l2src)
Input:- USB Camera(v4l2src)
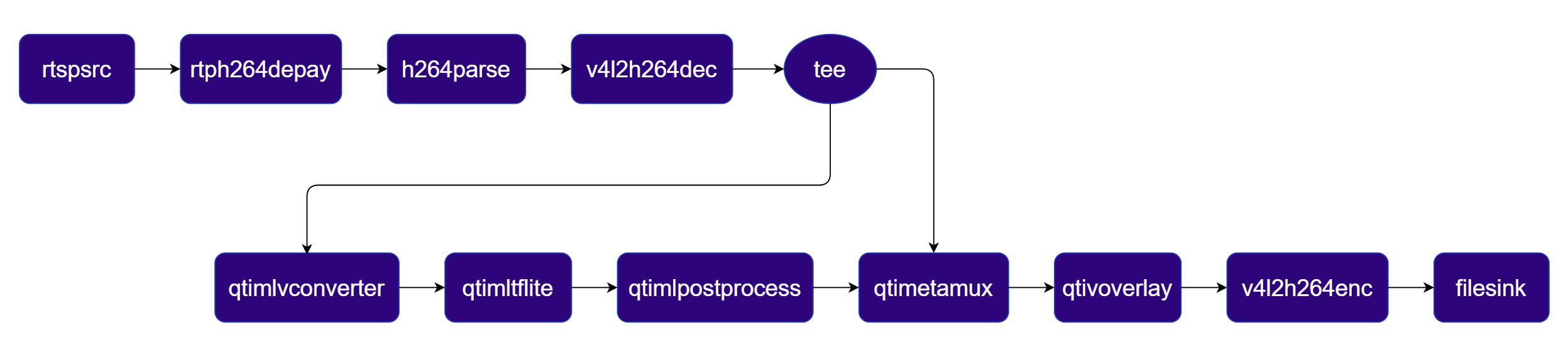
Input:- RTSP (rtspsrc)
Input:- RTSP (rtspsrc)
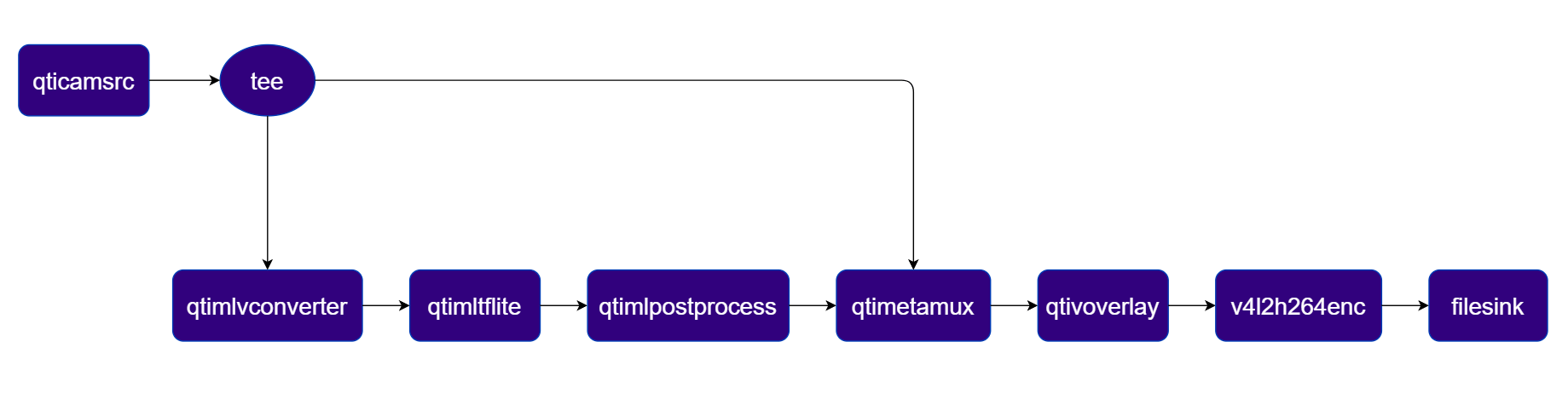
Input:- ISP Camera (qticamsrc)
Input:- ISP Camera (qticamsrc)
Plugins used in Pipeline
Plugins used in Pipeline
| Plugin | Description |
|---|---|
| filesrc | Reads an H.264 encoded video file as the pipeline source. |
| v4l2h264dec | Hardware-decodes the H.264 stream to raw NV12 frames using V4L2. |
| tee | Duplicates the decoded video stream for parallel video passthrough and ML inference branches. |
| qtimlvconverter | Preprocesses video frames (color conversion, scaling, normalization) and converts to tensor stream. |
| qtimltflite | Loads the TFLite model, applies the chosen delegate, and runs inference to produce result tensors. |
| qtimlpostprocess | Post-processes detection tensors, applies confidence threshold, and forwards bounding-box metadata. |
| qtimetamux | Merges video and metadata/text streams, attaching inference results as GST buffer metadata. |
| qtivoverlay | Overlays inference results (labels, bounding boxes, keypoints) onto the video frame using CL. |
| v4l2h264enc | Hardware-encodes the video stream to H.264 using V4L2. |
| filesink | Writes the encoded video stream to an output file. |
Two‑Stream Object Detection Pipeline
Object detection on Stream 1 with side‑by‑side composition on Stream 2 Pipeline Diagram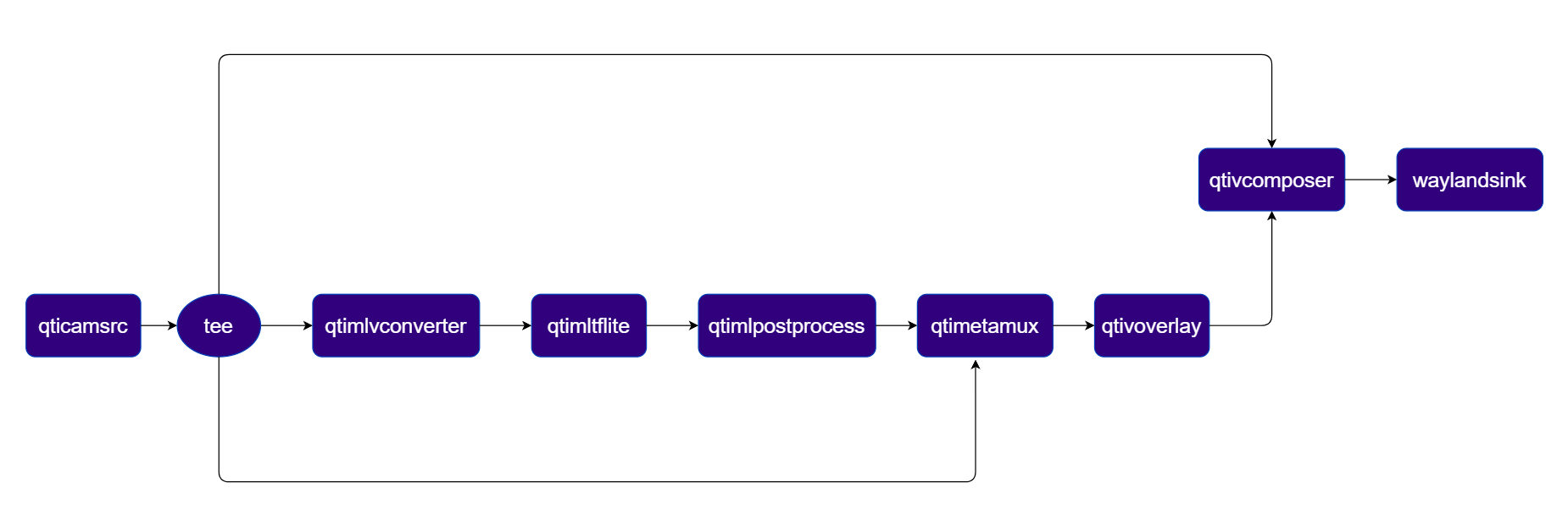
Try me
Try me
Download Required Files:
| File | Download | Save as |
|---|---|---|
| YOLOX W8A8 model | Qualcomm AI Hub — YOLOX | yolox_w8a8.tflite |
| Detection labels | yolov8.json | yolov8.json |
.zip archive, extract it on your host machine before copying:
unzip filename.zip
Plugins used in Pipeline
Plugins used in Pipeline
| Plugin | Description |
|---|---|
| qticamsrc | Captures live video from the ISP camera as the pipeline source. |
| tee | Splits the camera stream into three branches: raw passthrough, ML inference, and metadata mux. |
| qtimlvconverter | Preprocesses video frames (color conversion, scaling, normalization) and converts to tensor stream. |
| qtimltflite | Loads the TFLite model, applies the chosen delegate, and runs inference to produce result tensors. |
| qtimlpostprocess | Post-processes detection tensors, applies confidence threshold, and forwards bounding-box metadata. |
| qtimetamux | Merges video and metadata/text streams, attaching inference results as GST buffer metadata. |
| qtivoverlay | Overlays inference results (labels, bounding boxes, keypoints) onto the video frame using CL. |
| qtivcomposer | Composites the raw camera stream (sink_0) and the overlay stream (sink_1) side-by-side. |
| waylandsink | Renders the final composited video stream to a local display via Weston. |
Three-Stream Object Detection Pipeline
Object detection on Stream 1, side‑by‑side composition on Stream 2, and video encoding to file on Stream 3 Pipeline Diagram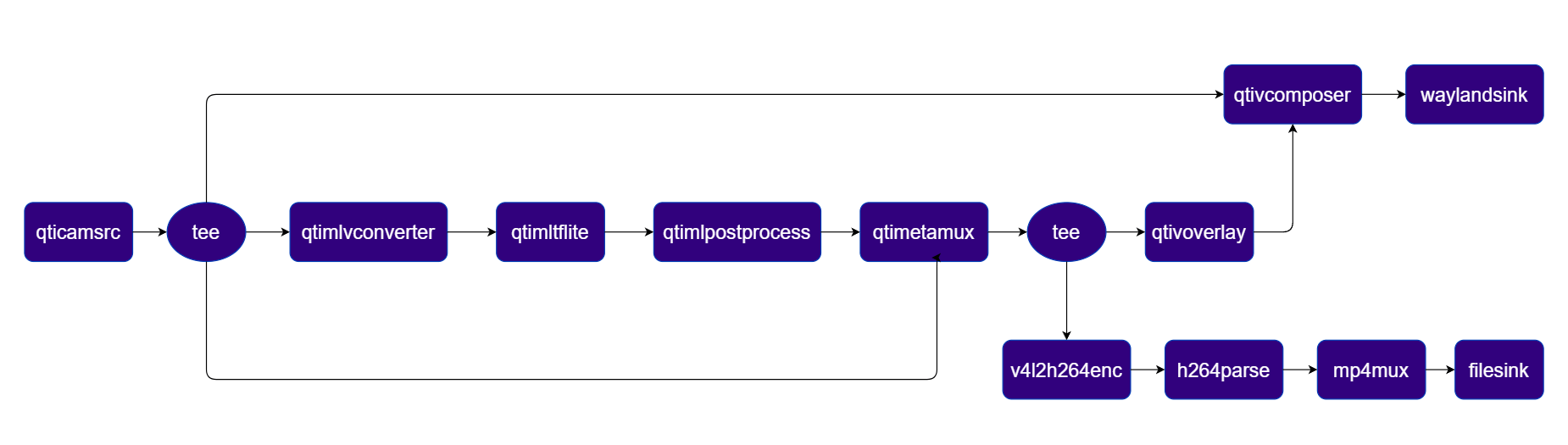
Try me
Try me
Download Required Files:
| File | Download | Save as |
|---|---|---|
| YOLOX W8A8 model | Qualcomm AI Hub — YOLOX | yolox_w8a8.tflite |
| Detection labels | yolov8.json | yolov8.json |
.zip archive, extract it on your host machine before copying:
unzip filename.zipPlugins used in Pipeline
Plugins used in Pipeline
| Plugin | Description |
|---|---|
| qticamsrc | Captures live video from the ISP camera as the pipeline source. |
| tee | Splits the stream into branches for display composition, ML inference, and file encoding. |
| qtimlvconverter | Preprocesses video frames (color conversion, scaling, normalization) and converts to tensor stream. |
| qtimltflite | Loads the TFLite model, applies the chosen delegate, and runs inference to produce result tensors. |
| qtimlpostprocess | Post-processes detection tensors, applies confidence threshold, and forwards bounding-box metadata. |
| qtimetamux | Merges video and metadata/text streams, attaching inference results as GST buffer metadata. |
| qtivcomposer | Composites the raw camera stream (sink_0) and the overlay stream (sink_1) side-by-side. |
| qtivoverlay | Overlays inference results (labels, bounding boxes, keypoints) onto the video frame using CL. |
| v4l2h264enc | Hardware-encodes the video stream to H.264 using V4L2. |
| filesink | Writes the encoded video stream to an output file. |
| waylandsink | Renders the final composited video stream to a local display via Weston. |
Face Detection
Detects faces using a quantized Face Detection Lite model accelerated via QNN (HTP backend). Pipeline Diagram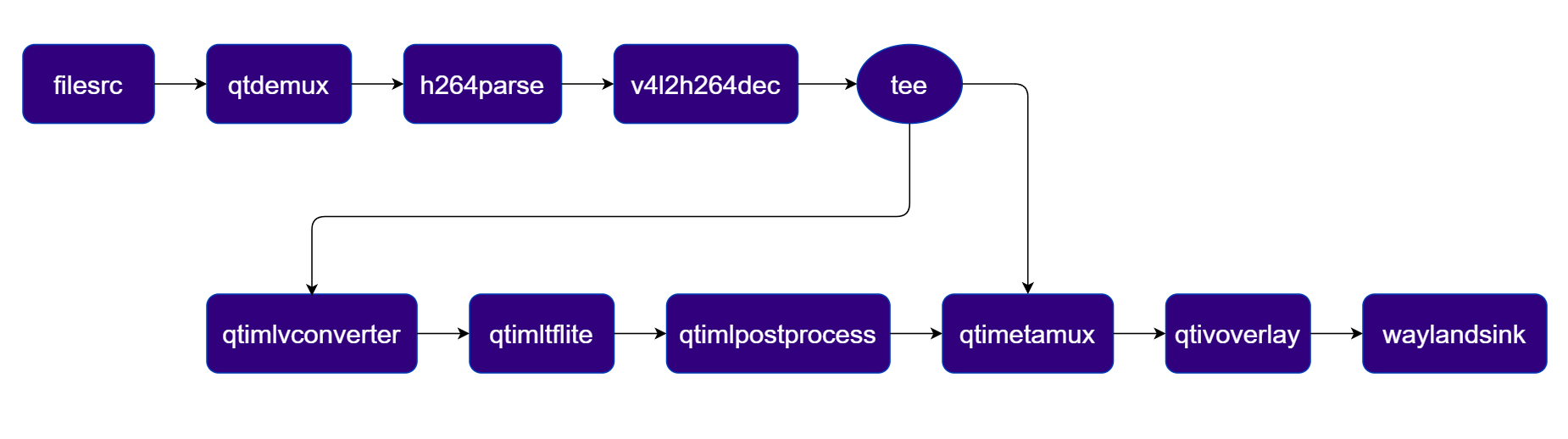
Try me
Try me
Download Required Files:
| File | Download | Save as |
|---|---|---|
| Face Detection Lite model | Qualcomm AI Hub — Face Detection Lite | face_det_lite_w8a8.tflite |
| Detection labels | face_det_lite labels | face_det_lite.json |
| Sample video | Input video | ai_demo_sample.mp4 |
.zip archive, extract it on your host machine before copying:
unzip filename.zip
Plugins used in Pipeline
Plugins used in Pipeline
| Plugin | Description |
|---|---|
| filesrc | Reads an H.264 encoded video file as the pipeline source. |
| v4l2h264dec | Hardware-decodes the H.264 stream to raw NV12 frames using V4L2. |
| tee | Splits the decoded stream for video passthrough and ML inference branches. |
| qtimlvconverter | Preprocesses video frames (color conversion, scaling, normalization) and converts to tensor stream. |
| qtimltflite | Loads the TFLite model, applies the chosen delegate, and runs inference to produce result tensors. |
| qtimlpostprocess | Post-processes face detection tensors and forwards bounding-box/landmark metadata. |
| qtimetamux | Merges video and metadata/text streams, attaching inference results as GST buffer metadata. |
| qtivoverlay | Overlays inference results (labels, bounding boxes, keypoints) onto the video frame using CL. |
| v4l2h264enc | Hardware-encodes the video stream to H.264 using V4L2. |
| filesink | Writes the encoded video stream to an output file. |
Image Classification
Classifies each video frame into predefined scene categories using the InceptionV3 LiteRT model and overlays the top classification results on the video stream. Pipeline Diagram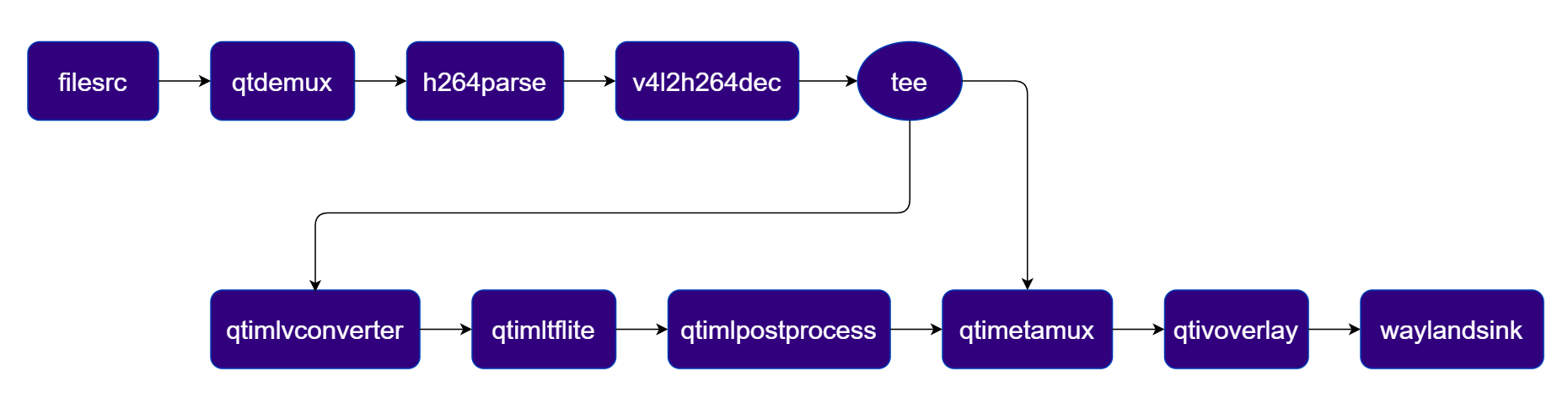
Try me
Try me
Download Required Files:
| File | Download | Save as |
|---|---|---|
| InceptionV3 model | Qualcomm AI Hub — InceptionV3 | mobilenet_v2_w8a8.tflite |
| Classification labels | mobilenet.json | mobilenet.json |
| Sample video | Input video | ai_demo_sample.mp4 |
.zip archive, extract it on your host machine before copying:
unzip filename.zip
Plugins used in Pipeline
Plugins used in Pipeline
| Plugin | Description |
|---|---|
| filesrc | Reads an H.264 encoded video file as the pipeline source. |
| v4l2h264dec | Hardware-decodes the H.264 stream to raw NV12 frames using V4L2. |
| tee | Splits the decoded stream for video passthrough and ML inference branches. |
| qtimlvconverter | Preprocesses video frames (color conversion, scaling, normalization) and converts to tensor stream. |
| qtimltflite | Loads the TFLite model, applies the chosen delegate, and runs inference to produce result tensors. |
| qtimlpostprocess | Post-processes classification tensors, applies confidence threshold, and produces top-N label text. |
| qtimetamux | Merges video and metadata/text streams, attaching inference results as GST buffer metadata. |
| qtivoverlay | Overlays inference results (labels, bounding boxes, keypoints) onto the video frame using CL. |
| v4l2h264enc | Hardware-encodes the video stream to H.264 using V4L2. |
| filesink | Writes the encoded video stream to an output file. |
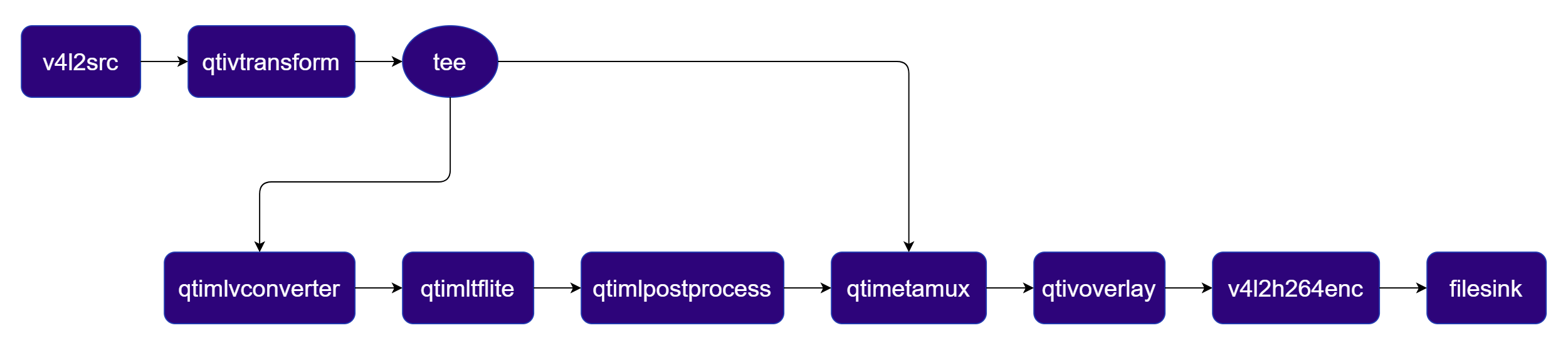
Segmentation
Performs pixel-wise semantic segmentation using DeepLabV3+ and blends the segmentation mask with the original video. Pipeline Diagram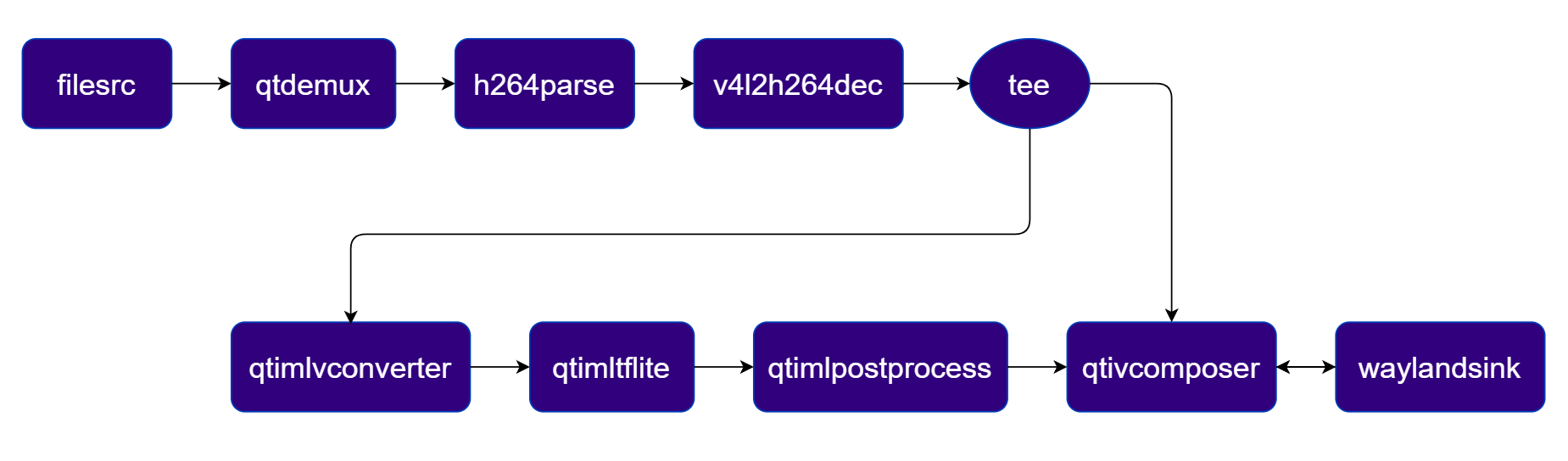
Try me
Try me
Download Required Files:
| File | Download | Save as |
|---|---|---|
| DeepLabV3+ model | Qualcomm AI Hub — DeepLabV3+ | deeplabv3_plus_mobilenet_w8a8.tflite |
| Segmentation labels | dv3-argmax.json | dv3-argmax.json |
| Sample video | Input video | ai_demo_sample.mp4 |
.zip archive, extract it on your host machine before copying:
unzip filename.zip
Plugins used in Pipeline
Plugins used in Pipeline
| Plugin | Description |
|---|---|
| filesrc | Reads an H.264 encoded video file as the pipeline source. |
| v4l2h264dec | Hardware-decodes the H.264 stream to raw NV12 frames using V4L2. |
| qtivtransform | Performs GPU-accelerated color/format conversion on the video frame. |
| tee | Splits the stream for video passthrough and ML inference branches. |
| qtimlvconverter | Preprocesses video frames (color conversion, scaling, normalization) and converts to tensor stream. |
| qtimltflite | Loads the TFLite model, applies the chosen delegate, and runs inference to produce result tensors. |
| qtimlpostprocess | Applies argmax post-processing to segmentation tensors and outputs an RGBA mask frame. |
| qtivcomposer | Blends the original video frame with the segmentation mask (alpha composite). |
| v4l2h264enc | Hardware-encodes the video stream to H.264 using V4L2. |
| filesink | Writes the encoded video stream to an output file. |
Pose Estimation
This pipeline performs real-time Human Pose Estimation using the HRNet Pose model. It analyzes video frames to identify individuals and precisely maps their anatomical keypoints (such as shoulders, elbows, knees, and ankles). It then generates a skeletal overlay on the video stream, allowing for the tracking of body posture and movement dynamics. Pipeline Diagram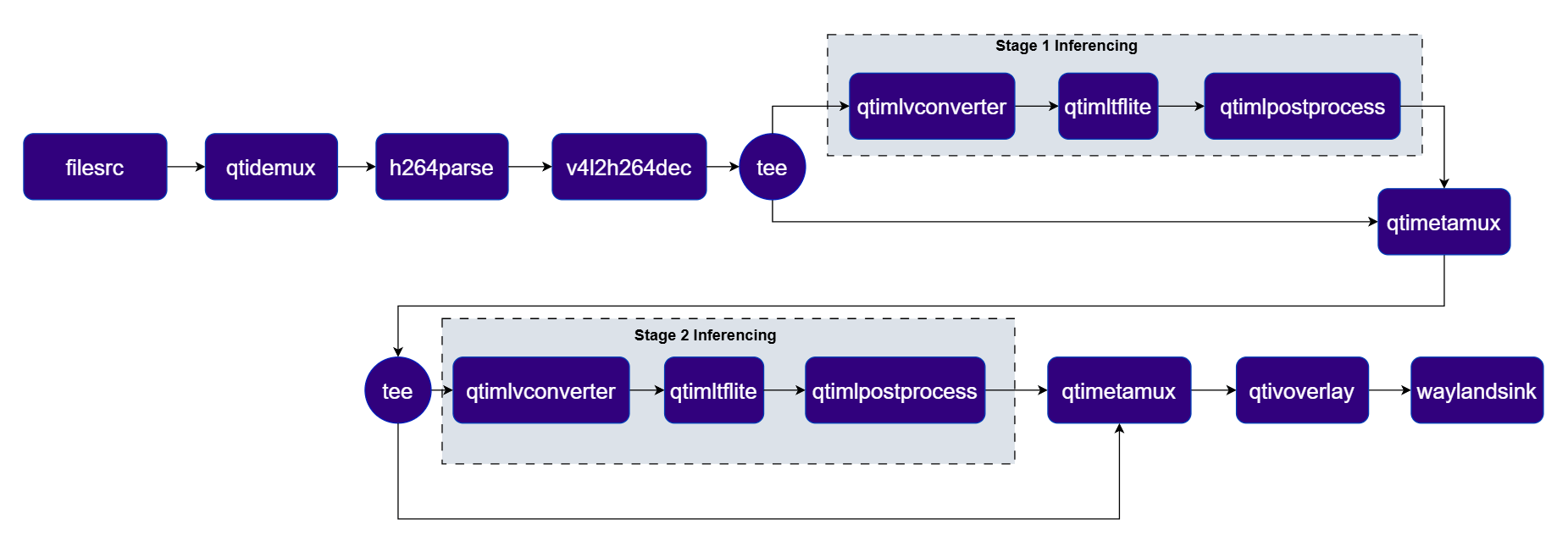
Try me
Try me
Download Required Files:
| File | Download | Save as |
|---|---|---|
| Person/foot detection model | Qualcomm AI Hub — HRNet Pose | person_foot_detection_w8a8.tflite |
| Person detection labels | foot_track_net.json | foot_track_net.json |
| HRNet pose model | Qualcomm AI Hub — HRNet Pose | hrnetpose_w8a8.tflite |
| Pose labels | hrnet.json | hrnet.json |
| Sample video | Input video | ai_demo_sample.mp4 |
foot_track_net_settings.json and hrnet_settings.json — these are included in the QIM SDK sample package at $HOME/labels/ on Qualcomm Linux or $HOME/models/ on Ubuntu..zip archive, extract it on your host machine before copying:
unzip filename.zipPlugins used in Pipeline
Plugins used in Pipeline
| Plugin | Description |
|---|---|
| filesrc | Reads an H.264 encoded video file as the pipeline source. |
| v4l2h264dec | Hardware-decodes the H.264 stream to raw NV12 frames using V4L2. |
| qtivtransform | Performs GPU-accelerated color/format conversion on the video frame. |
| tee | Splits the stream for video passthrough and person-detection inference. |
| qtimlvconverter | Preprocesses frames for Stage 1 (person detection) and Stage 2 (pose estimation) respectively. |
| qtimltflite | Runs Stage 1 (foot/person detection) and Stage 2 (HRNet pose estimation) inference sequentially. |
| qtimlpostprocess | Post-processes detection and pose tensors, producing keypoint metadata for overlay. |
| qtimetamux | Merges video and metadata/text streams, attaching inference results as GST buffer metadata. |
| qtivoverlay | Overlays inference results (labels, bounding boxes, keypoints) onto the video frame using CL. |
| v4l2h264enc | Hardware-encodes the video stream to H.264 using V4L2. |
| filesink | Writes the encoded video stream to an output file. |
AI Wall
This use-case demonstrates the capability to run 4 parallel AI inference sessions simultaneously using InceptionV3, Face Detection Lite, DeepLabV3+, and YOLOX. The results are composed into a single 2x2 grid display. This use case highlights the multi-stream processing and compositing capabilities of the platform. Pipeline Diagram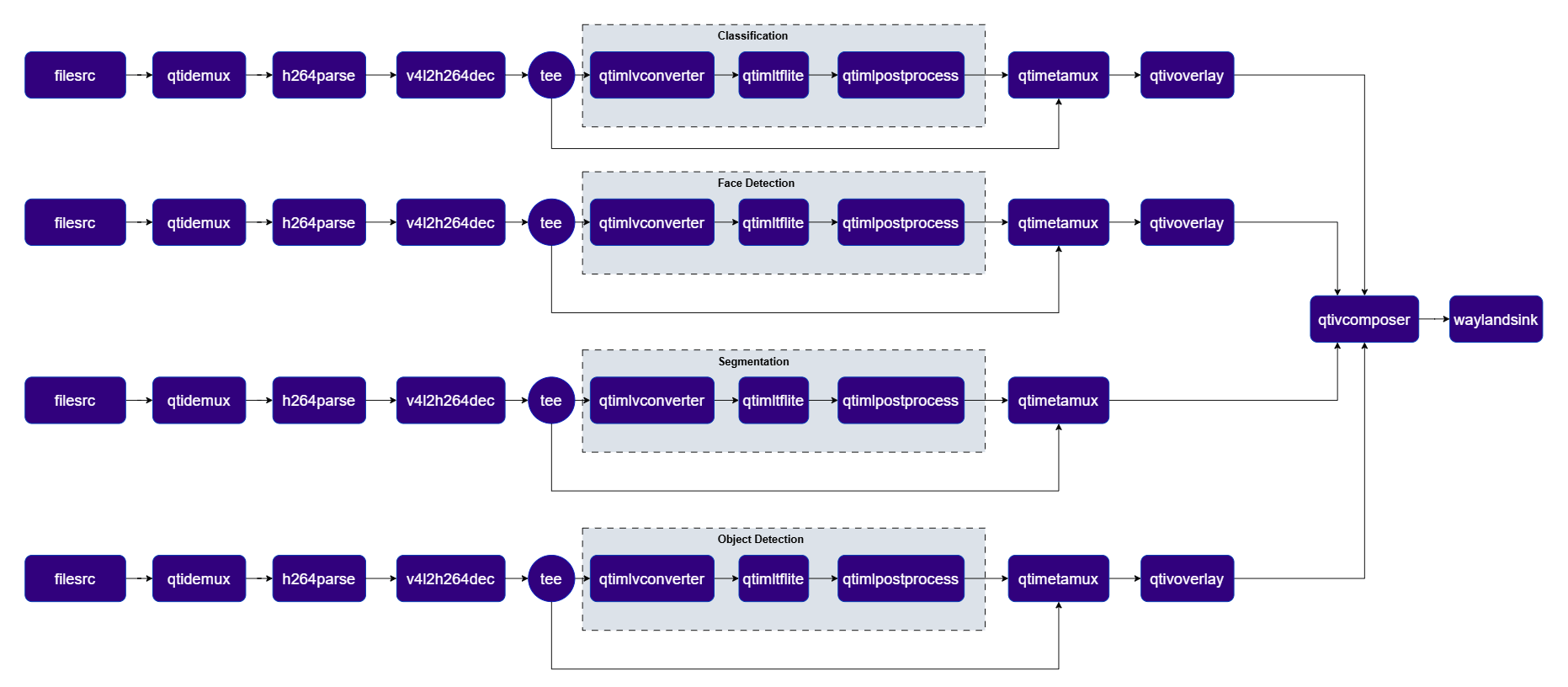
Try me
Try me
Download Required Files:
| File | Download | Save as |
|---|---|---|
| Classification model | Qualcomm AI Hub — InceptionV3 | mobilenet_v2_w8a8.tflite |
| Classification labels | mobilenet.json | mobilenet.json |
| Face detection model | Qualcomm AI Hub — Face Detection Lite | face_det_lite_w8a8.tflite |
| Face detection labels | face_det_lite labels | face_det_lite.json |
| Segmentation model | Qualcomm AI Hub — DeepLabV3+ | deeplabv3_plus_mobilenet_w8a8.tflite |
| Segmentation labels | dv3-argmax.json | dv3-argmax.json |
| Object detection model | Qualcomm AI Hub — YOLOX | yolox_w8a8.tflite |
| Object detection labels | yolov8.json | yolov8.json |
| Sample video | Input video | ai_demo_sample.mp4 |
.zip archive, extract it on your host machine before copying:
unzip filename.zipPlugins used in Pipeline
Plugins used in Pipeline
| Plugin | Description |
|---|---|
| filesrc | Four independent file sources feed the four parallel AI branches. |
| v4l2h264dec | Hardware-decodes each H.264 stream to raw NV12 frames using V4L2. |
| tee | Splits each branch stream for video passthrough and ML inference. |
| qtimlvconverter | Preprocesses each branch’s video frames into tensors for inference. |
| qtimltflite | Runs branch-specific inference: classification, face detection, segmentation, and object detection. |
| qtimlpostprocess | Post-processes each branch’s tensors (labels, bounding boxes, masks) for overlay or compositing. |
| qtimetamux | Merges video and metadata/text streams, attaching inference results as GST buffer metadata. |
| qtivcomposer | Composites all four inference-overlaid streams into a 2×2 grid display. |
| qtivoverlay | Overlays inference results (labels, bounding boxes, keypoints) onto the video frame using CL. |
| v4l2h264enc | Hardware-encodes the video stream to H.264 using V4L2. |
| filesink | Writes the encoded video stream to an output file. |
Super Resolution
Real-time AI video upscaling using quicksrnetlarge that reconstructs high-definition details from low-resolution inputs, visualized via a side-by-side comparison. Pipeline Diagram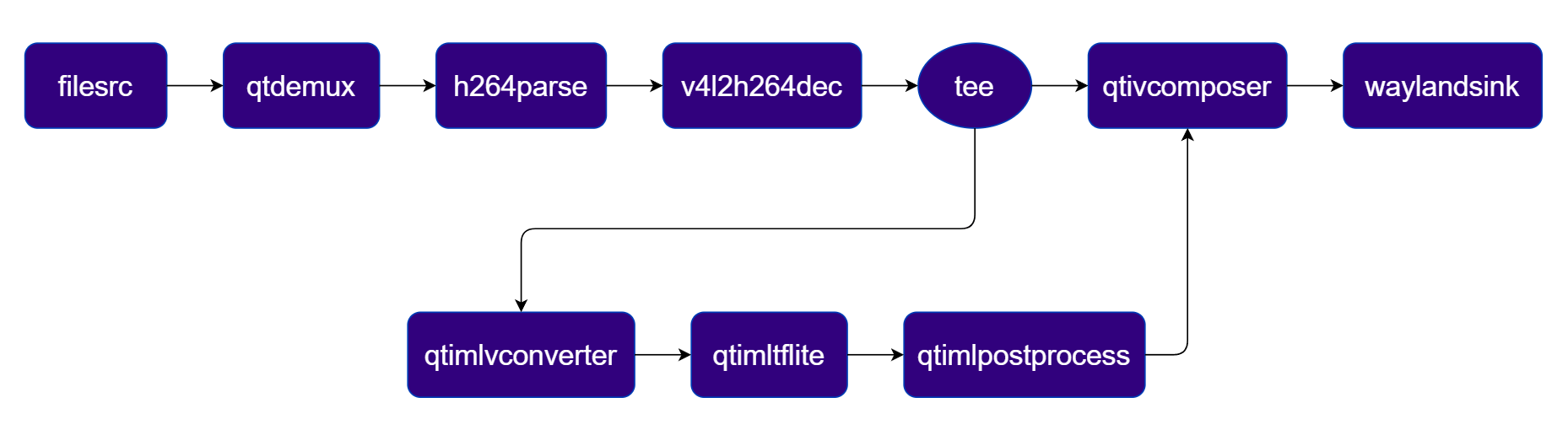
Try me
Try me
Download Required Files:
| File | Download | Save as |
|---|---|---|
| QuickSRNet Large model | Qualcomm AI Hub — QuickSRNet Large | quicksrnetlarge_w8a8.tflite |
| Sample video | Input video | ai_demo_sample.mp4 |
.zip archive, extract it on your host machine before copying:
unzip filename.zipPlugins used in Pipeline
Plugins used in Pipeline
| Plugin | Description |
|---|---|
| filesrc | Reads an H.264 encoded video file as the pipeline source. |
| v4l2h264dec | Hardware-decodes the H.264 stream to raw NV12 frames using V4L2. |
| tee | Splits the decoded stream — one branch for the original view, one for SR inference. |
| qtimlvconverter | Preprocesses video frames (color conversion, scaling, normalization) and converts to tensor stream. |
| qtimltflite | Loads the TFLite model, applies the chosen delegate, and runs inference to produce result tensors. |
| qtimlvsuperresolution | Applies the super-resolution post-processing module to reconstruct high-definition output. |
| qtivcomposer | Composites the original and upscaled streams side-by-side for comparison. |
| waylandsink | Renders the final composited video stream to a local display via Weston. |
Daisy Chain
Detection-Classification Daisy Chain
This section details the Detection-Classification Daisy Chain pipeline. This pipeline demonstrates a cascaded inference approach where the output of the YOLOX detection model is used to crop regions of interest (ROIs) which are then fed into the InceptionV3 classification model. Pipeline Diagram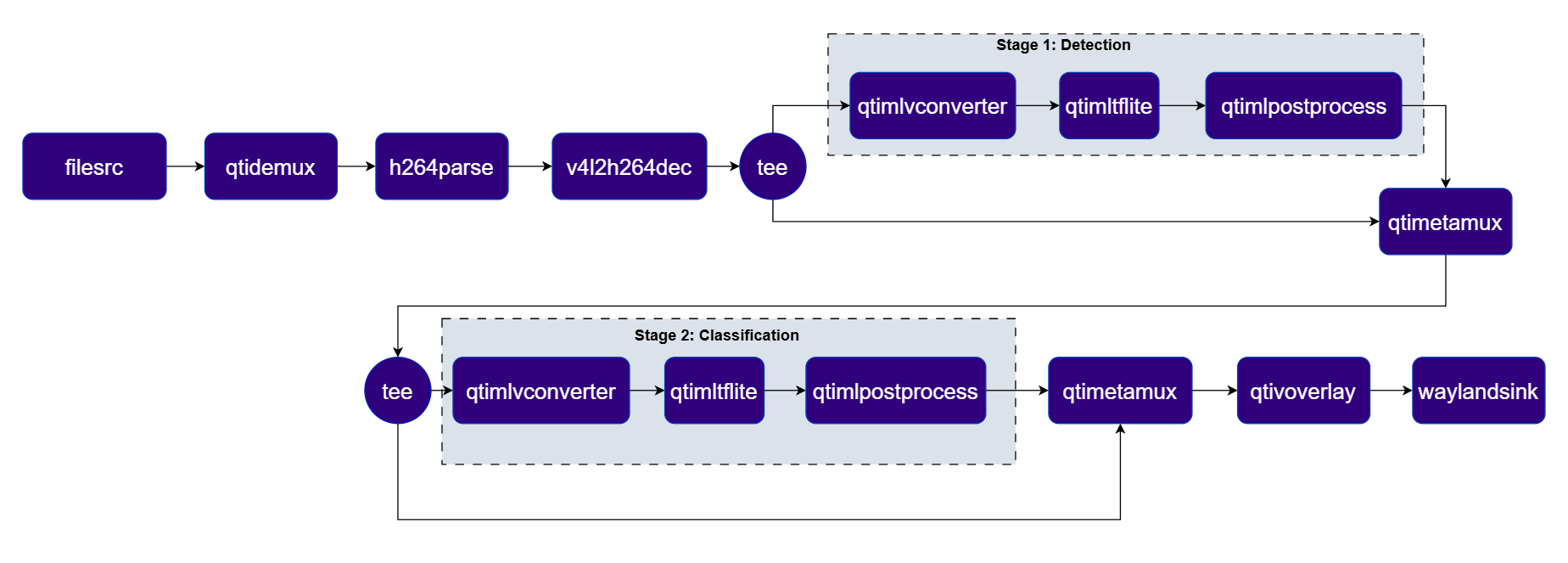
Try me
Try me
Download Required Files:
| File | Download | Save as |
|---|---|---|
| Detection model (YOLOX) | Qualcomm AI Hub — YOLOX | yolox_w8a8.tflite |
| Detection labels | yolov8.json | yolov8.json |
| Classification model (InceptionV3) | Qualcomm AI Hub — InceptionV3 | mobilenet_v2_w8a8.tflite |
| Classification labels | mobilenet.json | mobilenet.json |
| Sample video | Input video | ai_demo_sample.mp4 |
.zip archive, extract it on your host machine before copying:
unzip filename.zipPlugins used in Pipeline
Plugins used in Pipeline
| Plugin | Description |
|---|---|
| filesrc | Reads an H.264 encoded video file as the pipeline source. |
| v4l2h264dec | Hardware-decodes the H.264 stream to raw NV12 frames using V4L2. |
| tee | Splits the stream for Stage 1 video passthrough and YOLOX detection inference. |
| qtimlvconverter | Preprocesses frames for Stage 1 (YOLOX detection) and Stage 2 (MobileNet classification). |
| qtimltflite | Runs YOLOX (Stage 1) and MobileNet (Stage 2) inference sequentially. |
| qtimlpostprocess | Post-processes detection and classification tensors, forwarding structured metadata. |
| qtimetamux | Merges video and metadata/text streams, attaching inference results as GST buffer metadata. |
| qtivoverlay | Overlays inference results (labels, bounding boxes, keypoints) onto the video frame using CL. |
| waylandsink | Renders the final composited video stream to a local display via Weston. |
Gesture Recognition
A four-stage cascading pipeline that performs palm detection, hand landmark estimation, gesture embedding, and gesture classification on a live camera stream using ROI-based metadata propagation. Pipeline Diagram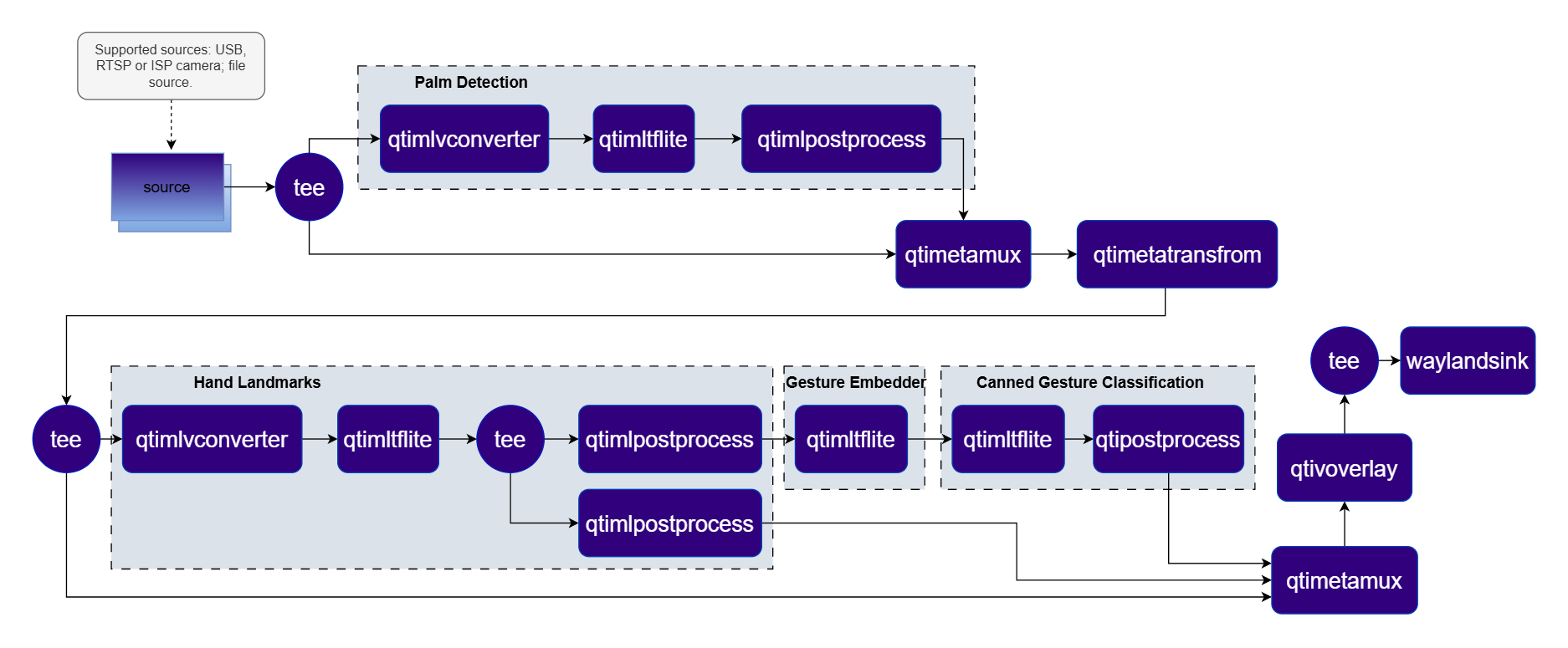
Try me
Try me
Download Required Files:
| File | Download | Save as |
|---|---|---|
| Palm detection model | See download steps above | hand_detector.tflite |
| Palm detection labels | palmd_labels.json | palmd_labels.json |
| Palm detection settings | palmd_settings.json | palmd_settings.json |
| Hand landmark model | See download steps above | hand_landmarks_detector.tflite |
| Hand landmark labels | hlandmark_labels.json | hlandmark_labels.json |
| Hand landmark settings | hlandmark_settings.json | hlandmark_settings.json |
| Gesture embedder model | See download steps above | gesture_embedder.tflite |
| Gesture classifier model | See download steps above | canned_gesture_classifier.tflite |
| Gesture labels | gesture_labels.json | gesture_labels.json |
Plugins used in Pipeline
Plugins used in Pipeline
| Plugin | Description |
|---|---|
| qticamsrc | Captures live video from the ISP camera as the pipeline source. |
| tee | Splits the stream for palm detection and downstream ROI-based stages. |
| qtimlvconverter | Preprocesses full frames (Stage 1) and ROI-cropped patches (Stage 2) for inference. |
| qtimltflite | Runs palm detection, hand landmark, gesture embedder, and gesture classifier inference sequentially. |
| qtimlpostprocess | Post-processes each stage’s tensors (palm ROIs, landmarks, gesture labels). |
| qtimetatransform | Transforms ROI palm-detection metadata into cropped regions for the landmark stage. |
| qtimetamux | Merges video and metadata/text streams, attaching inference results as GST buffer metadata. |
| qtivoverlay | Overlays inference results (labels, bounding boxes, keypoints) onto the video frame using CL. |
| waylandsink | Renders the final annotated video stream to a local display via Weston. |
Audio AI Pipelines
Audio Classification (FLAC File Decode)
Classifies audio events from a video file containing a FLAC audio track using YAMNet. The audio is decoded and processed in parallel with video playback, with classification results overlaid on the display. Pipeline Diagram
Try me
Try me
Download Required Files:
| File | Download | Save as |
|---|---|---|
| YAMNet model | Qualcomm AI Hub — YAMNet | yamnet.tflite |
| Audio classification labels | yamnet.json | yamnet.json |
| Sample video with FLAC audio | H264_720p_30fps_FLAC.mp4 | H264_720p_30fps_FLAC.mp4 |
.zip archive, extract it on your host machine before copying:
unzip filename.zipPlugins used in Pipeline
Plugins used in Pipeline
| Plugin | Description |
|---|---|
| filesrc | Reads an MP4 container file with H.264 video and FLAC audio as the source. |
| qtdemux | Demultiplexes the container into separate H.264 video and FLAC audio elementary streams. |
| h264parse | Parses the H.264 bitstream for downstream decoding. |
| v4l2h264dec | Hardware-decodes the H.264 stream to raw NV12 frames using V4L2. |
| flacparse | Parses the FLAC audio bitstream from the demuxed stream. |
| flacdec | Decodes the FLAC audio stream to raw PCM. |
| audioconvert | Converts decoded PCM to the required sample format (S16LE). |
| audioresample | Resamples the audio to the model’s required sample rate. |
| audiobuffersplit | Splits the audio into fixed-size buffers for frame-by-frame inference. |
| qtimlaconverter | Converts raw PCM audio into the feature representation expected by the model. |
| qtimltflite | Loads the TFLite model, applies the chosen delegate, and runs inference to produce result tensors. |
| qtimlaclassification | Post-processes audio inference tensors and produces classification label overlays. |
| qtivcomposer | Overlays the audio classification result panel onto the video playback stream. |
| waylandsink | Renders the final composited video stream to a local display via Weston. |