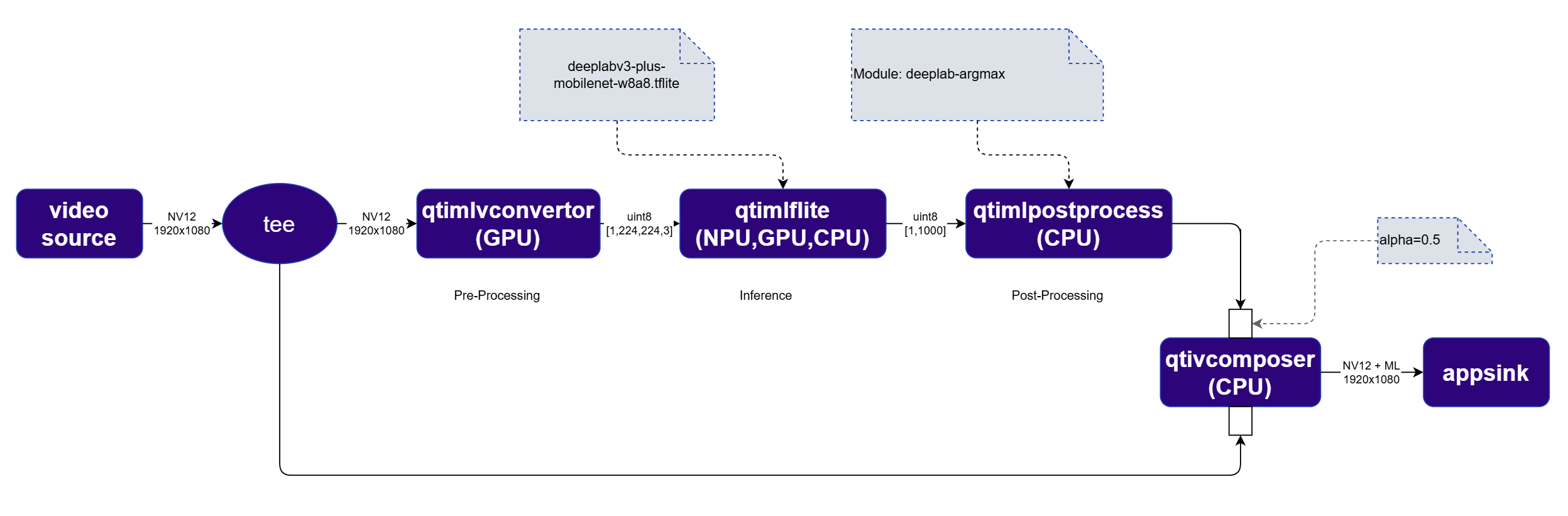
qtimlpostprocess plugin outputs an RGBA image mask rather than structured metadata. This mask is blended with the original video frame using qtivcomposer with sink_1::alpha=0.5. The qtivoverlay plugin is not needed for segmentation.
The order of inputs to qtivcomposer matters — the video frame must be connected first, and the segmentation mask second, so the mask is correctly composited on top.
Run example on device
Download Required Files
| File | Download | Save as |
|---|---|---|
| DeepLabV3+ MobileNet W8A8 model | Qualcomm AI Hub — DeepLabV3+ | deeplabv3_plus_mobilenet.tflite |
| Segmentation labels | dv3-argmax.json | dv3-argmax.json |
| Sample video | Input video | ai_demo_sample.mp4 |
If any downloaded file is a
.zip archive, extract it on your host machine before copying:
unzip filename.zipCopy files to device
Create the required directories and transfer the downloaded files to your device.
Expected output
The segmentation mask is blended on top of the original video frame in real time.