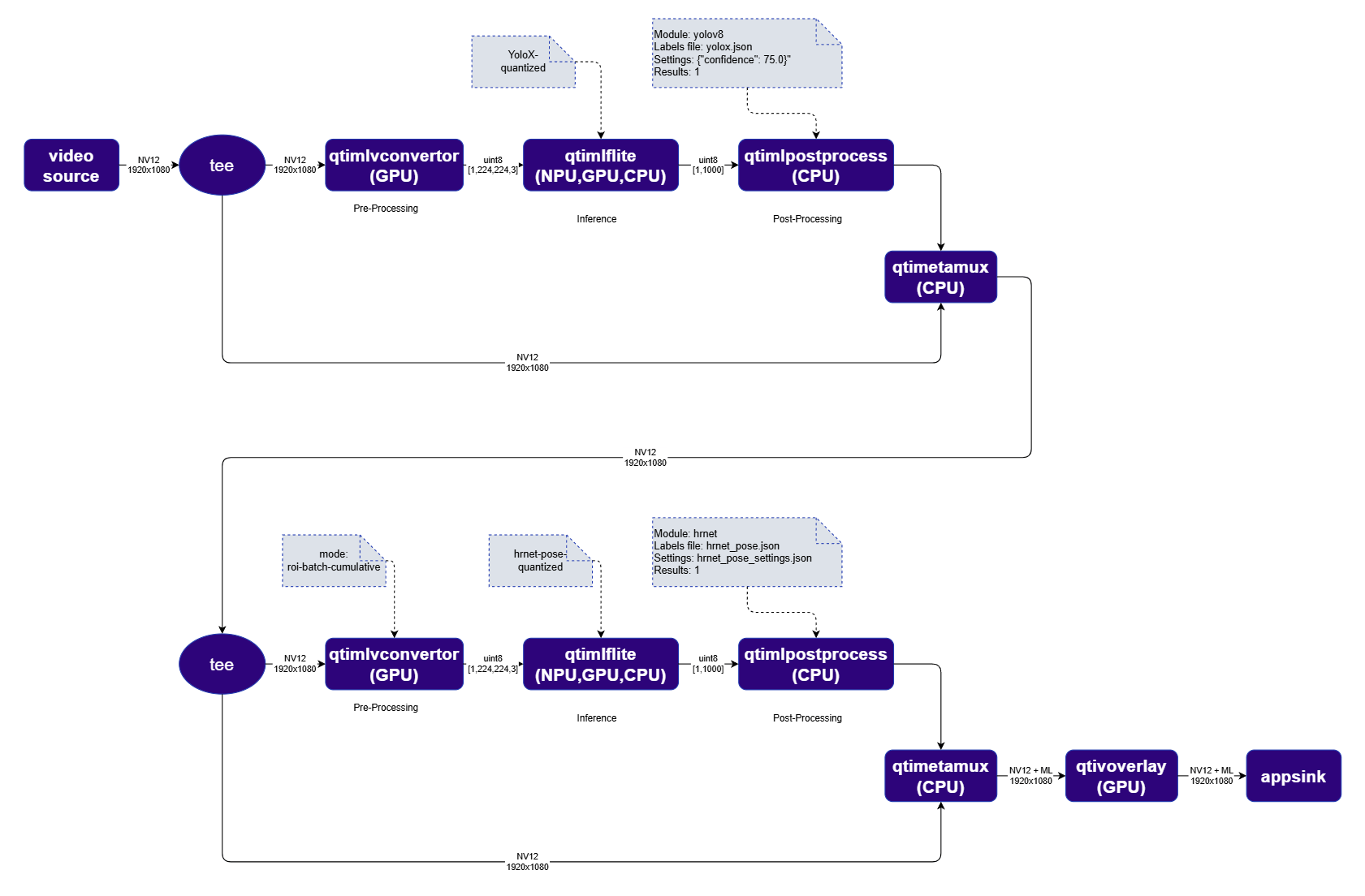
qtimlvconverter converts the NV12 frame to a tensor. qtimltflite runs FootTrackNet inference. qtimlpostprocess parses the output into bounding boxes for detected persons.
Stage 2 — Pose Estimation: qtimlvconverter in roi-batch-cumulative mode crops and centers each detected person’s bounding box into individual tensors. qtimltflite runs HRNet inference per person. qtimlpostprocess produces keypoints and skeleton connections.
All results are mapped back to the original frame and rendered by qtivoverlay.
Run example on device
Download Required Files
| File | Download | Save as |
|---|---|---|
| YOLOX W8A8 model | Qualcomm AI Hub — YOLOX | yolox_quantized.tflite |
| HRNet Pose W8A8 model | Qualcomm AI Hub — HRNet Pose | hrnet_pose_quantized.tflite |
| Detection labels | coco.txt | coco.txt |
| Pose labels | coco_pose.txt | coco_pose.txt |
| Pose settings | hrnet_settings.json | hrnet_pose_settings.json |
| Sample video | Input video | ai_demo_sample.mp4 |
If any downloaded file is a
.zip archive, extract it on your host machine before copying:
unzip filename.zipCopy files to device
Create the required directories and transfer the downloaded files to your device.
Expected output
Bounding boxes (from YOLOX) and skeleton keypoints (from HRNet) are overlaid on each video frame in real time.Exploring output options
Thewaylandsink in the pipeline above can be replaced with other output elements:
Encode to file:
rtsp://<device-ip>:8900/live.