Build a four-stage real-time hand gesture recognition pipeline using Qualcomm IM SDK — covering palm detection, hand landmark estimation, gesture embedding, and gesture classification, all running on-device with hardware-accelerated inference.
Introduction
Real-time gesture recognition is redefining how humans interact with machines — enabling touchless, natural interfaces across augmented reality, gaming, accessibility, and industrial control. But accurately interpreting hand gestures demands more than simple object detection; it requires a multi-stage AI pipeline capable of progressively refining raw visual input into high-level, actionable intent. The QIM SDK brings this capability directly to the edge. By routing compute-intensive tasks through hardware-accelerated GStreamer plugins, the SDK offloads video decoding, frame preparation, multi-stage inference, and encoding entirely to dedicated hardware blocks — delivering low-latency, power-efficient execution even for complex multi-model workloads. At the core of this use case is a four-stage sequential inference pipeline:Stage 1
Stage 2
Stage 3
Stage 4
Use Case Overview
Source
Palm Detection
Hand Landmark Detection
Gesture Embedding
Gesture Classification
Metadata Synchronization
qtimetamux synchronizes this structured metadata with the original video frames, maintaining per-frame consistency throughout the pipeline.Pipeline diagram
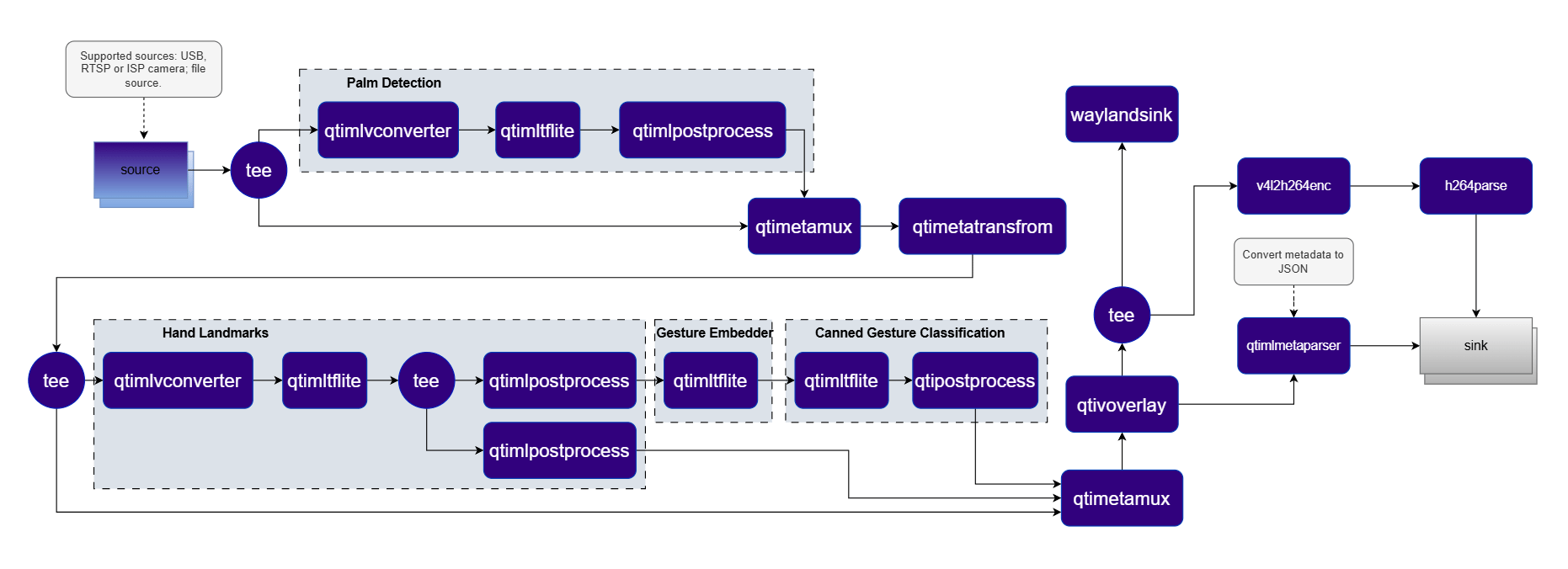
Elements used in pipeline
| Element | Description |
|---|---|
source | Accepts video input from a USB camera, ISP camera, RTSP stream, or local video file. |
tee | Splits the stream into multiple parallel branches for simultaneous processing. |
qtimlvconverter | Hardware-accelerated resize, YUV→RGB conversion, and pixel normalization to meet each model’s input requirements. |
qtimltflite | Executes TFLite inference models, producing raw output tensors. |
qtimlpostprocess | Decodes raw tensors into structured bounding boxes, keypoints, labels, and confidence scores via dynamically loaded modules. |
qtimetamux | Synchronizes inference results with the original video stream as structured per-frame metadata. |
qtimetatransform | Transforms metadata as it flows through the pipeline — modifying coordinate systems to ensure compatibility with downstream elements. |
qtivoverlay | Composites bounding boxes, keypoints, and labels onto video frames using hardware-accelerated overlay rendering. |
qtimlmetaparser | Serializes per-frame inference metadata into JSON for integration with external systems. |
v4l2h264enc / h264parse | Hardware-accelerated H.264 encoding of the processed video stream. |
waylandsink | Renders the output to the local display via the Wayland compositor. |
How It Works
Stage 1 — Palm Detection
qtimetatransform element uses this information to compute an affine transformation matrix, which is attached as metadata and carried forward to the next stage.Affine Crop Generation
qtimlvconverter instance consumes the affine transformation matrix and applies it to crop and rotate the detected hand region from the original frame, producing a correctly aligned input for the next stage.Stage 2 — Hand Landmark Detection
Stage 3 — Gesture Embedding
Stage 4 — Gesture Classification
Hierarchical Metadata
Run application on device
Setup Requirements
Hardware
| Component | Description |
|---|---|
| Edge Device | RB3 Gen 2, IQ8, or IQ9 — Primary processing unit for AI inference and video composition. |
| Camera Source | IP/RTSP camera, ISP (on-device) camera, or USB camera. A local file source may be substituted if no physical camera is available. |
| HDMI Display Monitor | Connected to the edge device for rendering and visualizing pipeline output. |
| PoE Switch | Powers IP/RTSP cameras and provides network connectivity over a single Ethernet cable per camera. (Required for IP/RTSP camera setups only.) |
| Local Network | Ensures the edge device, RTSP camera, and host machine are reachable on the same network. (Required when using RTSP camera input or streaming results via RTSP or WebRTC.) |
Software
Flash your Qualcomm Edge device by following the device setup and flashing instructions here Once your device is ready, follow the instructions below to set up the Gesture Recognition AI Pipeline:AI Model and config files
Download the gesture recognizer models from Google MediaPipe:| File | Download | Save as |
|---|---|---|
| Palm detection model | See download steps above | palm_detection.tflite |
| Hand landmark model | See download steps above | hand_landmark.tflite |
| Gesture embedder model | See download steps above | gesture_embedder.tflite |
| Gesture classifier model | See download steps above | canned_gesture_classifier.tflite |
| Palm detection labels | palmd_labels.json | palmd_labels.json |
| Palm detection settings | palmd_settings.json | palmd_settings.json |
| Hand landmark labels | hlandmark_labels.json | hlandmark_labels.json |
| Hand landmark settings | hlandmark_settings.json | hlandmark_settings.json |
| Gesture labels | gesture_labels.json | gesture_labels.json |
| Sample video | Input video | video.mp4 |
--no-display flag to run in headless mode.USB camera
USB camera
RTSP camera
RTSP camera
File input
File input
Headless (no display)
Headless (no display)
Note: This example uses an offline video file as input. To use an IP/RTSP camera or USB camera instead, update the --input-type argument accordingly — refer to the Command-Line Options section below for details.
It produces two key output results: an AI-annotated video stream and a JSON metadata stream. To visualize these results, refer to the Host-Side Visualization section below.
Visualize the Results - Host-Side Visualization (Windows + WSL)
This section describes how to run the visualization client on a Windows host machine using WSL (Windows Subsystem for Linux). The client renders the live video stream alongside a real-time AI metadata panel. 📥 The visualization client script can be downloaded here: rtsp_webrtc_client.zip It displays:- Left panel — Live video stream with AI overlays (bounding boxes, keypoints, gesture labels)
- Right panel — Real-time AI metadata (JSON): object detections, bounding boxes, and confidence scores.
RTSP
RTSP
WebRTC
WebRTC
| Panel | Content |
|---|---|
| Left | Real-time decoded video stream with gesture overlays |
| Right | Live AI metadata — detected hands, keypoints, and gesture labels |

Command-Line Options
--input-type
--input-type
| Value | Description |
|---|---|
usb | USB camera. Requires --input-config=/dev/video0. |
isp | Built-in ISP (on-device) camera. Optionally specify a camera ID via --input-config=0. |
rtsp | External IP/RTSP camera or stream. Requires --input-config=rtsp://.... |
file | Local H.264-encoded video file. Requires --input-config=/path/to/video.mp4. |
--input-config
--input-config
--input-type.| Input Type | Value |
|---|---|
| USB | /dev/videoX |
| ISP | <camera ID> |
| RTSP | rtsp://<ip-or-url> |
| File | /path/to/video.mp4 |
--output-type
--output-type
| Value | Description |
|---|---|
none | No video output (headless mode). |
file | Save encoded output to a file. Requires --output-config=/path/to/output.mp4. |
rtsp | Stream over RTSP. Requires --output-config=<port>. Access at rtsp://<device-ip>:<port>/live. |
webrtc | Stream over WebRTC. Requires --output-config=ws://<signalling-server>:<port>. |
--output-config
--output-config
--output-type.| Output Type | Value |
|---|---|
| File | /path/to/output.mp4 |
| RTSP | <port> |
| WebRTC | ws://<signalling-server>:<port> |
--model-base-path
--model-base-path
| Asset type | Resolved path |
|---|---|
Model files (*.tflite) | <base-path>/models/<file> |
Label / settings files (*.json) | <base-path>/labels/<file> |
--no-display
--no-display
--width / --height / --framerate
--width / --height / --framerate
--webrtc-id
--webrtc-id
JSON Metadata Output
The pipeline generates structured per-frame metadata. Each detected hand produces a root entry with child landmark, embedding, and classification results:Sample JSON output
Sample JSON output
Implementation Deep-Dive
1. Application Configuration and Runtime Context
1. Application Configuration and Runtime Context
2. Pipeline Assembly
2. Pipeline Assembly
3. Multi-Stage Inference Model Configuration
3. Multi-Stage Inference Model Configuration
qtimltflite instance and a task-specific qtimlpostprocess module:4. Linking Palm and Hand Landmark Branches
4. Linking Palm and Hand Landmark Branches
5. Gesture Branch and Output
5. Gesture Branch and Output
6. WebRTC Signaling
6. WebRTC Signaling
libsoup:| Callback | Responsibility |
|---|---|
on_offer_created | Constructs and sends the SDP offer to the remote peer |
on_ice_candidate | Transmits ICE candidates to the signaling server |
on_ws_message | Handles incoming signaling messages from the WebSocket |
Build the Application
- Source code: gst-gesture-recognition
- Build instructions: Steps to build custom application