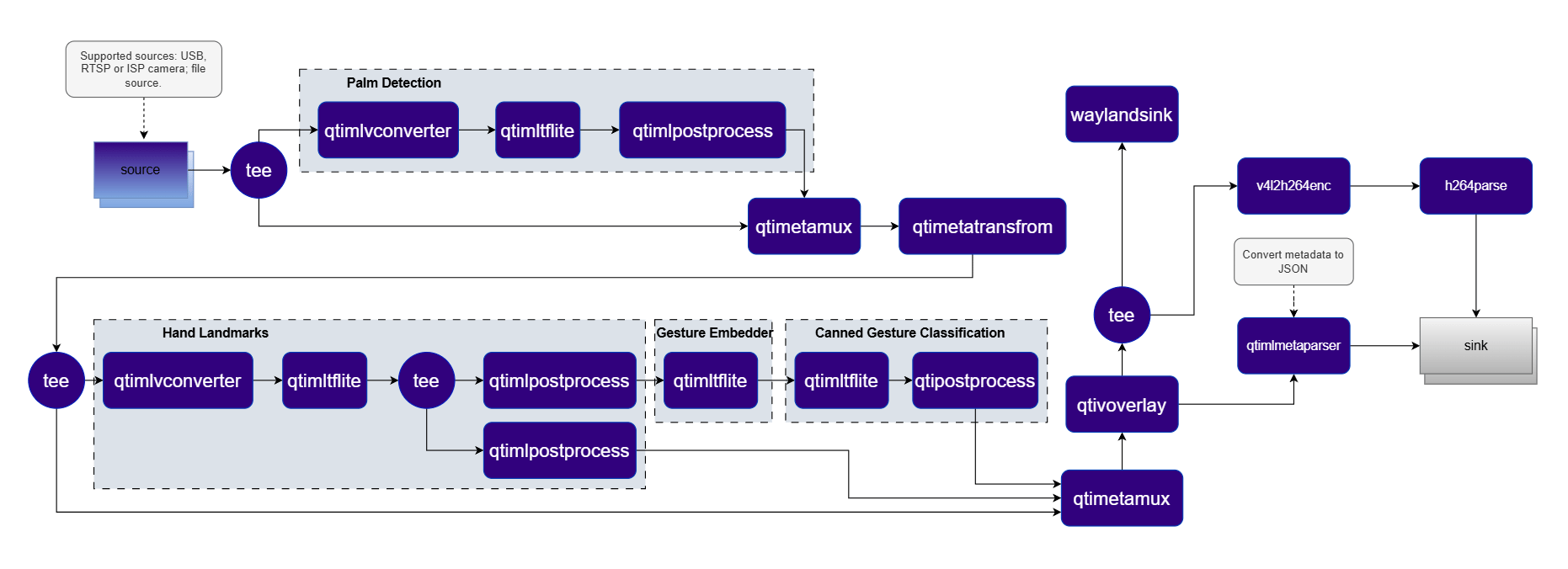
 ## Elements used in pipeline
| Element | Description |
| ---------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------- |
| `source` | Accepts video input from a USB camera, ISP camera, RTSP stream, or local video file. |
| `tee` | Splits the stream into multiple parallel branches for simultaneous processing. |
| [`qtimlvconverter`](../plugin-reference/qtimlvconverter) | Hardware-accelerated resize, YUV→RGB conversion, and pixel normalization to meet each model's input requirements. |
| [`qtimltflite`](../plugin-reference/qtimltflite) | Executes TFLite inference models, producing raw output tensors. |
| [`qtimlpostprocess`](../plugin-reference/qtimlpostprocess) | Decodes raw tensors into structured bounding boxes, keypoints, labels, and confidence scores via dynamically loaded modules. |
| [`qtimetamux`](../plugin-reference/qtimetamux) | Synchronizes inference results with the original video stream as structured per-frame metadata. |
| `qtimetatransform` | Transforms metadata as it flows through the pipeline — modifying coordinate systems to ensure compatibility with downstream elements. |
| [`qtivoverlay`](../plugin-reference/qtivoverlay) | Composites bounding boxes, keypoints, and labels onto video frames using hardware-accelerated overlay rendering. |
| [`qtimlmetaparser`](../plugin-reference/qtimetaparser) | Serializes per-frame inference metadata into JSON for integration with external systems. |
| `v4l2h264enc` / `h264parse` | Hardware-accelerated H.264 encoding of the processed video stream. |
| [`waylandsink`](../plugin-reference/waylandsink) | Renders the output to the local display via the Wayland compositor. |
## How It Works
## Elements used in pipeline
| Element | Description |
| ---------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------- |
| `source` | Accepts video input from a USB camera, ISP camera, RTSP stream, or local video file. |
| `tee` | Splits the stream into multiple parallel branches for simultaneous processing. |
| [`qtimlvconverter`](../plugin-reference/qtimlvconverter) | Hardware-accelerated resize, YUV→RGB conversion, and pixel normalization to meet each model's input requirements. |
| [`qtimltflite`](../plugin-reference/qtimltflite) | Executes TFLite inference models, producing raw output tensors. |
| [`qtimlpostprocess`](../plugin-reference/qtimlpostprocess) | Decodes raw tensors into structured bounding boxes, keypoints, labels, and confidence scores via dynamically loaded modules. |
| [`qtimetamux`](../plugin-reference/qtimetamux) | Synchronizes inference results with the original video stream as structured per-frame metadata. |
| `qtimetatransform` | Transforms metadata as it flows through the pipeline — modifying coordinate systems to ensure compatibility with downstream elements. |
| [`qtivoverlay`](../plugin-reference/qtivoverlay) | Composites bounding boxes, keypoints, and labels onto video frames using hardware-accelerated overlay rendering. |
| [`qtimlmetaparser`](../plugin-reference/qtimetaparser) | Serializes per-frame inference metadata into JSON for integration with external systems. |
| `v4l2h264enc` / `h264parse` | Hardware-accelerated H.264 encoding of the processed video stream. |
| [`waylandsink`](../plugin-reference/waylandsink) | Renders the output to the local display via the Wayland compositor. |
## How It Works
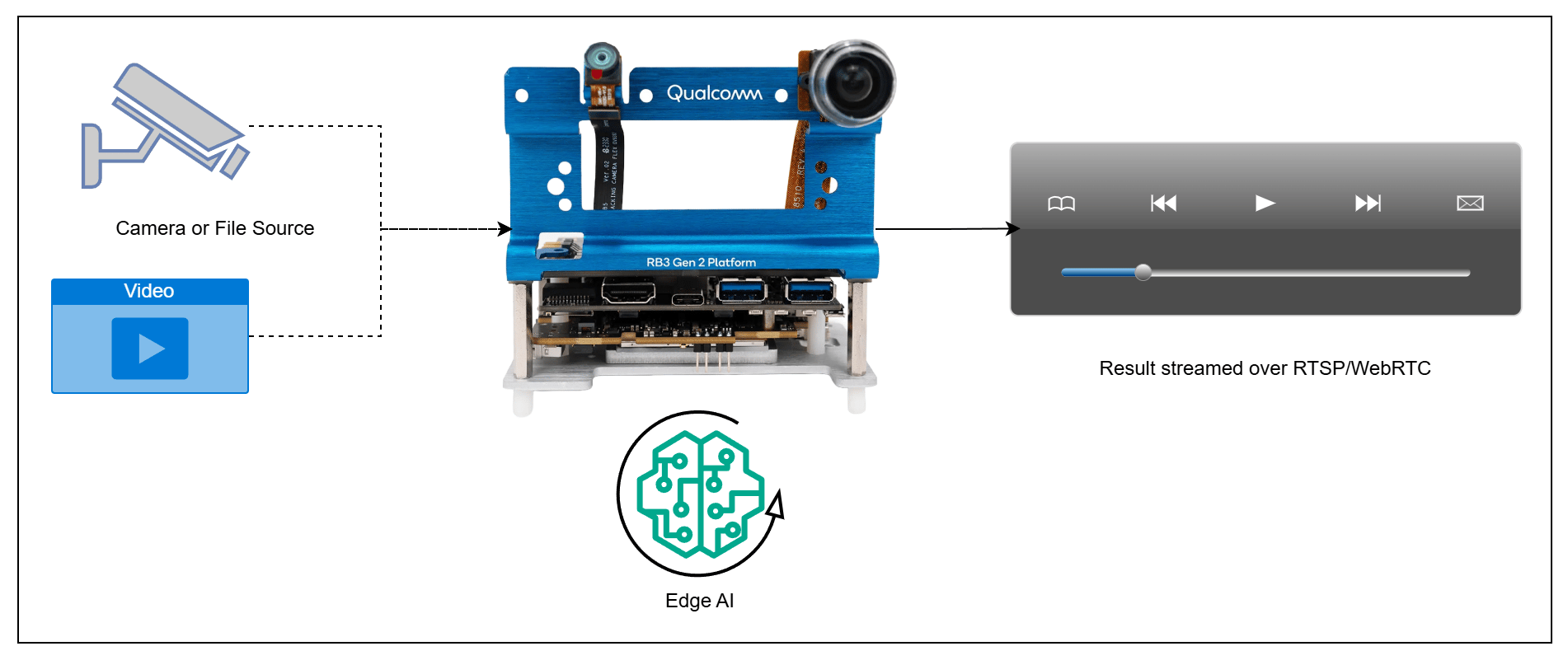 | Component | Description |
| ------------------------ | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| **Edge Device** | RB3 Gen 2, IQ8, or IQ9 — Primary processing unit for AI inference and video composition. |
| **Camera Source** | IP/RTSP camera, ISP (on-device) camera, or USB camera. A local file source may be substituted if no physical camera is available. |
| **HDMI Display Monitor** | Connected to the edge device for rendering and visualizing pipeline output. |
| **PoE Switch** | Powers IP/RTSP cameras and provides network connectivity over a single Ethernet cable per camera. (Required for IP/RTSP camera setups only.) |
| **Local Network** | Ensures the edge device, RTSP camera, and host machine are reachable on the same network. (Required when using RTSP camera input or streaming results via RTSP or WebRTC.) |
#### Software
**Flash your Qualcomm Edge device** by following the device setup and flashing instructions [here](../installation)
**Once your device is ready**, follow the instructions below to set up the Gesture Recognition AI Pipeline:
##### AI Model and config files
Download the gesture recognizer models from Google MediaPipe:
```bash theme={null}
# Download the gesture recognizer task bundle
wget https://storage.googleapis.com/mediapipe-models/gesture_recognizer/gesture_recognizer/float16/latest/gesture_recognizer.task
# Extract the top-level task
unzip gesture_recognizer.task
# Extract hand landmarker models
unzip hand_landmarker.task
# save hand_detector.tflite as palm_detection.tflite
# save hand_landmarks_detector.tflite as hand_landmark.tflite
# Extract gesture recognizer models
unzip hand_gesture_recognizer.task
# → gesture_embedder.tflite, canned_gesture_classifier.tflite
```
| Component | Description |
| ------------------------ | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| **Edge Device** | RB3 Gen 2, IQ8, or IQ9 — Primary processing unit for AI inference and video composition. |
| **Camera Source** | IP/RTSP camera, ISP (on-device) camera, or USB camera. A local file source may be substituted if no physical camera is available. |
| **HDMI Display Monitor** | Connected to the edge device for rendering and visualizing pipeline output. |
| **PoE Switch** | Powers IP/RTSP cameras and provides network connectivity over a single Ethernet cable per camera. (Required for IP/RTSP camera setups only.) |
| **Local Network** | Ensures the edge device, RTSP camera, and host machine are reachable on the same network. (Required when using RTSP camera input or streaming results via RTSP or WebRTC.) |
#### Software
**Flash your Qualcomm Edge device** by following the device setup and flashing instructions [here](../installation)
**Once your device is ready**, follow the instructions below to set up the Gesture Recognition AI Pipeline:
##### AI Model and config files
Download the gesture recognizer models from Google MediaPipe:
```bash theme={null}
# Download the gesture recognizer task bundle
wget https://storage.googleapis.com/mediapipe-models/gesture_recognizer/gesture_recognizer/float16/latest/gesture_recognizer.task
# Extract the top-level task
unzip gesture_recognizer.task
# Extract hand landmarker models
unzip hand_landmarker.task
# save hand_detector.tflite as palm_detection.tflite
# save hand_landmarks_detector.tflite as hand_landmark.tflite
# Extract gesture recognizer models
unzip hand_gesture_recognizer.task
# → gesture_embedder.tflite, canned_gesture_classifier.tflite
```
 The pipeline generates structured JSON metadata in the following format:
```bash theme={null}
{
"object_detection": [
{
"label": "palm",
"confidence": 85.94279479980469,
"color": 16711935,
"rectangle": {
"x": 0.3484375,
"y": 0.15555555555555556,
"width": 0.22708333333333333,
"height": 0.40370370370370373
},
"xtraparams": {
"affine-matrix": [
0.42060701741537004,
1.2300771264034409,
38.53241177825402,
-1.2300771264034409,
0.42060701741537004,
1313.4940252711156,
0.0,
0.0,
1.0
]
},
"video_landmarks": [
{
"keypoints": [
{ "keypoint": "wrist", "x": 0.5411458333333333, "y": 0.42407407407407405, "confidence": 99.70703125, "color": 16711935 },
{ "keypoint": "thumb cmc", "x": 0.5432291666666667, "y": 0.3648148148148148, "confidence": 99.70703125, "color": 16711935 },
{ "keypoint": "thumb mcp", "x": 0.5359375, "y": 0.3037037037037037, "confidence": 99.70703125, "color": 16711935 },
{ "keypoint": "thumb ip", "x": 0.5348958333333333, "y": 0.24537037037037038, "confidence": 99.70703125, "color": 16711935 },
{ "keypoint": "thumb tip", "x": 0.5395833333333333, "y": 0.1925925925925926, "confidence": 99.70703125, "color": 16711935 },
{ "keypoint": "index finger mcp", "x": 0.47760416666666666, "y": 0.32962962962962963, "confidence": 99.70703125, "color": 16711935 },
{ "keypoint": "index finger pip", "x": 0.43854166666666666, "y": 0.29907407407407405, "confidence": 99.70703125, "color": 16711935 },
{ "keypoint": "index finger dip", "x": 0.4109375, "y": 0.2814814814814815, "confidence": 99.70703125, "color": 16711935 },
{ "keypoint": "index finger tip", "x": 0.3848958333333333, "y": 0.26666666666666666, "confidence": 99.70703125, "color": 16711935 },
{ "keypoint": "middle finger mcp", "x": 0.4635416666666667, "y": 0.37407407407407406, "confidence": 99.70703125, "color": 16711935 },
{ "keypoint": "middle finger pip", "x": 0.41822916666666665, "y": 0.36203703703703705, "confidence": 99.70703125, "color": 16711935 },
{ "keypoint": "middle finger dip", "x": 0.3880208333333333, "y": 0.35648148148148145, "confidence": 99.70703125, "color": 16711935 },
{ "keypoint": "middle finger tip", "x": 0.36041666666666666, "y": 0.3537037037037037, "confidence": 99.70703125, "color": 16711935 },
{ "keypoint": "ring finger mcp", "x": 0.46197916666666666, "y": 0.41759259259259257, "confidence": 99.70703125, "color": 16711935 },
{ "keypoint": "ring finger pip", "x": 0.4192708333333333, "y": 0.4212962962962963, "confidence": 99.70703125, "color": 16711935 },
{ "keypoint": "ring finger dip", "x": 0.39114583333333336, "y": 0.425, "confidence": 99.70703125, "color": 16711935 },
{ "keypoint": "ring finger tip", "x": 0.36614583333333334, "y": 0.42777777777777776, "confidence": 99.70703125, "color": 16711935 },
{ "keypoint": "pinky mcp", "x": 0.46979166666666666, "y": 0.45462962962962963, "confidence": 99.70703125, "color": 16711935 },
{ "keypoint": "pinky pip", "x": 0.43802083333333336, "y": 0.475, "confidence": 99.70703125, "color": 16711935 },
{ "keypoint": "pinky dip", "x": 0.41822916666666665, "y": 0.49074074074074076, "confidence": 99.70703125, "color": 16711935 },
{ "keypoint": "pinky tip", "x": 0.39947916666666666, "y": 0.5027777777777778, "confidence": 99.70703125, "color": 16711935 }
],
"links": [
{ "start": 0, "end": 17 },
{ "start": 1, "end": 0 },
{ "start": 2, "end": 1 },
{ "start": 3, "end": 2 },
{ "start": 4, "end": 3 },
{ "start": 5, "end": 0 },
{ "start": 6, "end": 5 },
{ "start": 7, "end": 6 },
{ "start": 8, "end": 7 },
{ "start": 9, "end": 5 },
{ "start": 10, "end": 9 },
{ "start": 11, "end": 10 },
{ "start": 12, "end": 11 },
{ "start": 13, "end": 9 },
{ "start": 14, "end": 13 },
{ "start": 15, "end": 14 },
{ "start": 16, "end": 15 },
{ "start": 17, "end": 13 },
{ "start": 18, "end": 17 },
{ "start": 19, "end": 18 },
{ "start": 20, "end": 19 }
]
}
],
"image_classification": [
{
"label": "Open Palm",
"confidence": 0.7060546875,
"color": 4294902015
}
]
}
],
"parameters": {
"timestamp": "28356149027"
}
}
```
Beyond the default setup, the application offers flexible input and output configurations that can be tailored via command-line options, as described below:
## Command-Line Options
The pipeline generates structured JSON metadata in the following format:
```bash theme={null}
{
"object_detection": [
{
"label": "palm",
"confidence": 85.94279479980469,
"color": 16711935,
"rectangle": {
"x": 0.3484375,
"y": 0.15555555555555556,
"width": 0.22708333333333333,
"height": 0.40370370370370373
},
"xtraparams": {
"affine-matrix": [
0.42060701741537004,
1.2300771264034409,
38.53241177825402,
-1.2300771264034409,
0.42060701741537004,
1313.4940252711156,
0.0,
0.0,
1.0
]
},
"video_landmarks": [
{
"keypoints": [
{ "keypoint": "wrist", "x": 0.5411458333333333, "y": 0.42407407407407405, "confidence": 99.70703125, "color": 16711935 },
{ "keypoint": "thumb cmc", "x": 0.5432291666666667, "y": 0.3648148148148148, "confidence": 99.70703125, "color": 16711935 },
{ "keypoint": "thumb mcp", "x": 0.5359375, "y": 0.3037037037037037, "confidence": 99.70703125, "color": 16711935 },
{ "keypoint": "thumb ip", "x": 0.5348958333333333, "y": 0.24537037037037038, "confidence": 99.70703125, "color": 16711935 },
{ "keypoint": "thumb tip", "x": 0.5395833333333333, "y": 0.1925925925925926, "confidence": 99.70703125, "color": 16711935 },
{ "keypoint": "index finger mcp", "x": 0.47760416666666666, "y": 0.32962962962962963, "confidence": 99.70703125, "color": 16711935 },
{ "keypoint": "index finger pip", "x": 0.43854166666666666, "y": 0.29907407407407405, "confidence": 99.70703125, "color": 16711935 },
{ "keypoint": "index finger dip", "x": 0.4109375, "y": 0.2814814814814815, "confidence": 99.70703125, "color": 16711935 },
{ "keypoint": "index finger tip", "x": 0.3848958333333333, "y": 0.26666666666666666, "confidence": 99.70703125, "color": 16711935 },
{ "keypoint": "middle finger mcp", "x": 0.4635416666666667, "y": 0.37407407407407406, "confidence": 99.70703125, "color": 16711935 },
{ "keypoint": "middle finger pip", "x": 0.41822916666666665, "y": 0.36203703703703705, "confidence": 99.70703125, "color": 16711935 },
{ "keypoint": "middle finger dip", "x": 0.3880208333333333, "y": 0.35648148148148145, "confidence": 99.70703125, "color": 16711935 },
{ "keypoint": "middle finger tip", "x": 0.36041666666666666, "y": 0.3537037037037037, "confidence": 99.70703125, "color": 16711935 },
{ "keypoint": "ring finger mcp", "x": 0.46197916666666666, "y": 0.41759259259259257, "confidence": 99.70703125, "color": 16711935 },
{ "keypoint": "ring finger pip", "x": 0.4192708333333333, "y": 0.4212962962962963, "confidence": 99.70703125, "color": 16711935 },
{ "keypoint": "ring finger dip", "x": 0.39114583333333336, "y": 0.425, "confidence": 99.70703125, "color": 16711935 },
{ "keypoint": "ring finger tip", "x": 0.36614583333333334, "y": 0.42777777777777776, "confidence": 99.70703125, "color": 16711935 },
{ "keypoint": "pinky mcp", "x": 0.46979166666666666, "y": 0.45462962962962963, "confidence": 99.70703125, "color": 16711935 },
{ "keypoint": "pinky pip", "x": 0.43802083333333336, "y": 0.475, "confidence": 99.70703125, "color": 16711935 },
{ "keypoint": "pinky dip", "x": 0.41822916666666665, "y": 0.49074074074074076, "confidence": 99.70703125, "color": 16711935 },
{ "keypoint": "pinky tip", "x": 0.39947916666666666, "y": 0.5027777777777778, "confidence": 99.70703125, "color": 16711935 }
],
"links": [
{ "start": 0, "end": 17 },
{ "start": 1, "end": 0 },
{ "start": 2, "end": 1 },
{ "start": 3, "end": 2 },
{ "start": 4, "end": 3 },
{ "start": 5, "end": 0 },
{ "start": 6, "end": 5 },
{ "start": 7, "end": 6 },
{ "start": 8, "end": 7 },
{ "start": 9, "end": 5 },
{ "start": 10, "end": 9 },
{ "start": 11, "end": 10 },
{ "start": 12, "end": 11 },
{ "start": 13, "end": 9 },
{ "start": 14, "end": 13 },
{ "start": 15, "end": 14 },
{ "start": 16, "end": 15 },
{ "start": 17, "end": 13 },
{ "start": 18, "end": 17 },
{ "start": 19, "end": 18 },
{ "start": 20, "end": 19 }
]
}
],
"image_classification": [
{
"label": "Open Palm",
"confidence": 0.7060546875,
"color": 4294902015
}
]
}
],
"parameters": {
"timestamp": "28356149027"
}
}
```
Beyond the default setup, the application offers flexible input and output configurations that can be tailored via command-line options, as described below:
## Command-Line Options