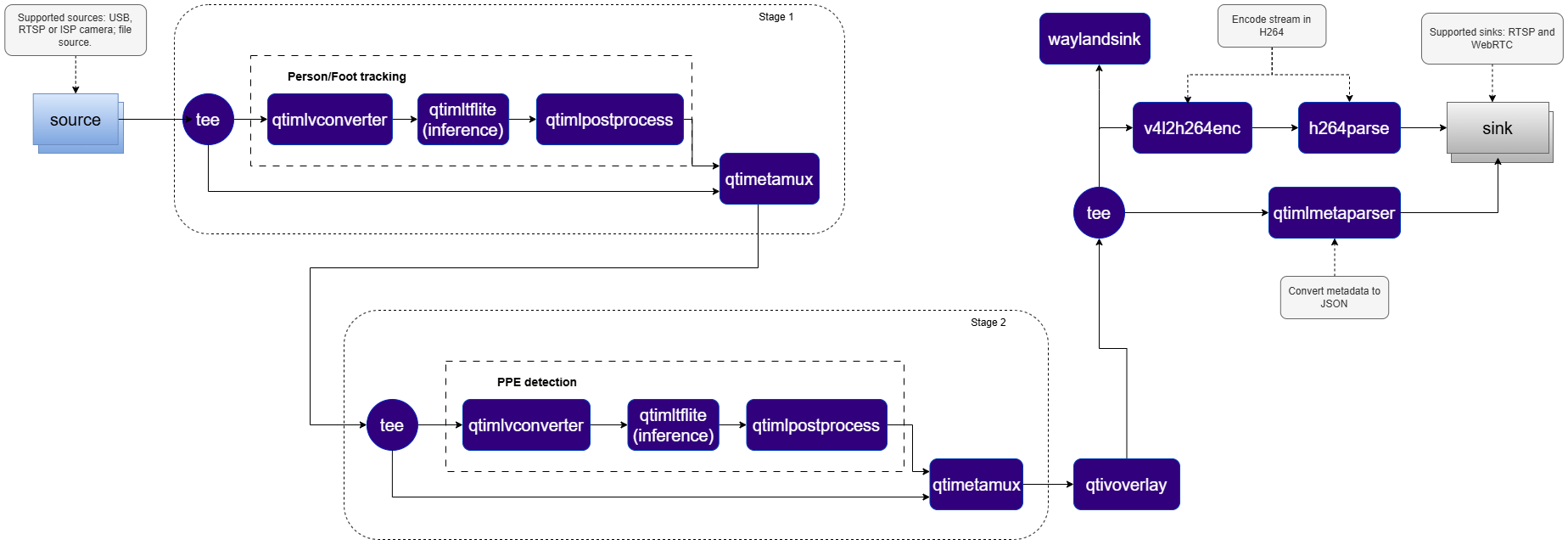
 ## Elements used in pipeline
| Element | Description |
| -------------------------------------------------------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `source` | Accepts input from an RTSP camera, ISP camera, USB camera, or a local file. |
| `tee` | Splits the incoming stream into multiple parallel branches for simultaneous downstream processing. |
| [`qtimlvconverter`](../plugin-reference/qtimlvconverter) | Prepares video frames for inference by performing resizing, YUV-to-RGB color space conversion, and pixel normalization to match the model's input requirements. |
| [`qtimltflite`](../plugin-reference/qtimltflite) | Executes the TFLite inference model for person/feet detection on each incoming frame. |
| [`qtimlpostprocess`](../plugin-reference/qtimlpostprocess) | Decodes raw output tensors into structured bounding boxes and labels. Post-processing logic is implemented as a dynamically loaded module, enabling model-specific strategies to be swapped without pipeline changes. |
| [`qtimetamux`](../plugin-reference/qtimetamux) | Synchronizes inference results with the original video stream and attaches them as per-frame structured metadata. |
| [`qtivoverlay`](../plugin-reference/qtivoverlay) | Renders bounding boxes, labels, and the restricted zone polygon directly onto video frames for real-time visual feedback. |
| [`qtimetaparser`](../plugin-reference/qtimetaparser) | Serializes per-frame ML metadata into JSON format for integration with external monitoring and analytics systems. |
| [`v4l2h264enc`](../plugin-reference/v4l2h264enc) / `h264parse` | Encodes the processed video stream into H.264 format for downstream transmission or storage. |
| `sink` | Streams the encoded video and associated metadata over RTSP or WebRTC via the `rtspbin` or `webrtcbin` plugins respectively, enabling remote clients to consume results in real time. |
| [`waylandsink`](../plugin-reference/waylandsink) | Renders the annotated video stream to a local Wayland display. |
## How it works
The PPE detection pipeline implements a **two-stage daisy-chain architecture**, where two sequential AI models operate in tandem — the output of the first model directly driving the execution of the second.
* **Stage 1 — Person Detection:** The first AI model processes the full video frame and produces bounding boxes identifying the location of each individual in the scene.
* **Crop Generation:** Since the second PPE detection model requires image crops — not bounding boxes — as input, a second instance of [`qtimlvconverter`](../plugin-reference/qtimlvconverter) operates in crop generation mode, receiving the bounding boxes produced by the first model and dynamically generating a cropped image region from the original frame for each detected person.
* **Stage 2 — PPE Detection:** The PPE detection model is invoked once per detected person, analyzing each cropped region independently to identify the presence or absence of safety equipment — including helmets, vests, gloves, and masks.
* **Metadata Re-attachment:** A second [`qtimetamux`](../plugin-reference/qtimetamux) instance re-attaches the PPE detection results to the original video stream, ensuring all detections are synchronized with the corresponding frame and person.
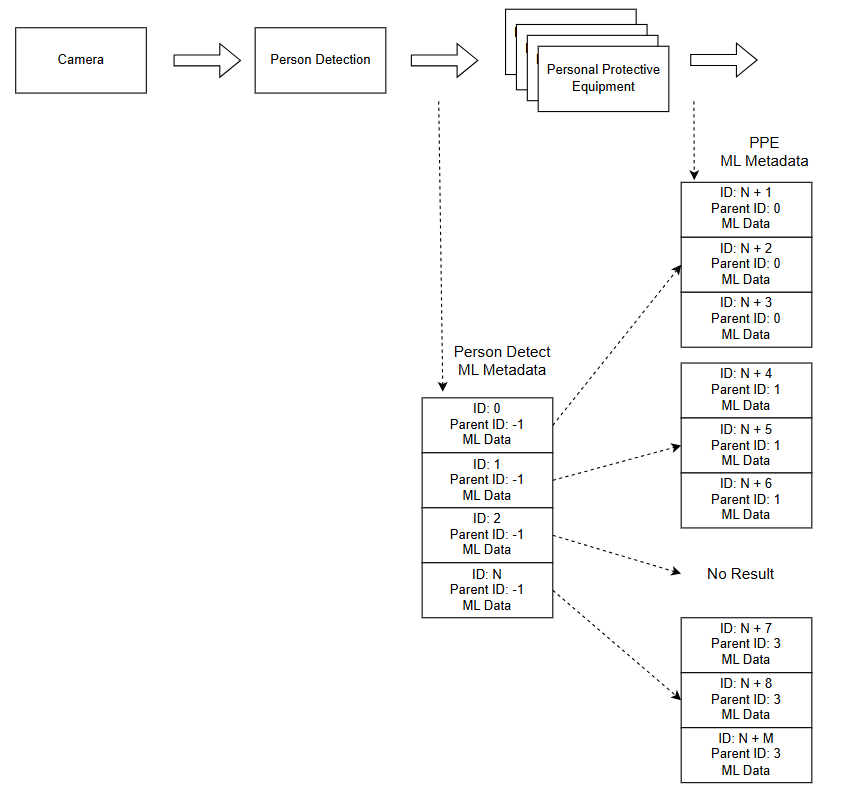
* **Hierarchical Metadata:** To preserve logical relationships across both model stages, the pipeline employs a **hierarchical metadata model** based on unique IDs and parent IDs — explicitly linking each PPE detection to its corresponding individual, enabling accurate per-person visualization, tracking, and downstream analytics.
## Elements used in pipeline
| Element | Description |
| -------------------------------------------------------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `source` | Accepts input from an RTSP camera, ISP camera, USB camera, or a local file. |
| `tee` | Splits the incoming stream into multiple parallel branches for simultaneous downstream processing. |
| [`qtimlvconverter`](../plugin-reference/qtimlvconverter) | Prepares video frames for inference by performing resizing, YUV-to-RGB color space conversion, and pixel normalization to match the model's input requirements. |
| [`qtimltflite`](../plugin-reference/qtimltflite) | Executes the TFLite inference model for person/feet detection on each incoming frame. |
| [`qtimlpostprocess`](../plugin-reference/qtimlpostprocess) | Decodes raw output tensors into structured bounding boxes and labels. Post-processing logic is implemented as a dynamically loaded module, enabling model-specific strategies to be swapped without pipeline changes. |
| [`qtimetamux`](../plugin-reference/qtimetamux) | Synchronizes inference results with the original video stream and attaches them as per-frame structured metadata. |
| [`qtivoverlay`](../plugin-reference/qtivoverlay) | Renders bounding boxes, labels, and the restricted zone polygon directly onto video frames for real-time visual feedback. |
| [`qtimetaparser`](../plugin-reference/qtimetaparser) | Serializes per-frame ML metadata into JSON format for integration with external monitoring and analytics systems. |
| [`v4l2h264enc`](../plugin-reference/v4l2h264enc) / `h264parse` | Encodes the processed video stream into H.264 format for downstream transmission or storage. |
| `sink` | Streams the encoded video and associated metadata over RTSP or WebRTC via the `rtspbin` or `webrtcbin` plugins respectively, enabling remote clients to consume results in real time. |
| [`waylandsink`](../plugin-reference/waylandsink) | Renders the annotated video stream to a local Wayland display. |
## How it works
The PPE detection pipeline implements a **two-stage daisy-chain architecture**, where two sequential AI models operate in tandem — the output of the first model directly driving the execution of the second.
* **Stage 1 — Person Detection:** The first AI model processes the full video frame and produces bounding boxes identifying the location of each individual in the scene.
* **Crop Generation:** Since the second PPE detection model requires image crops — not bounding boxes — as input, a second instance of [`qtimlvconverter`](../plugin-reference/qtimlvconverter) operates in crop generation mode, receiving the bounding boxes produced by the first model and dynamically generating a cropped image region from the original frame for each detected person.
* **Stage 2 — PPE Detection:** The PPE detection model is invoked once per detected person, analyzing each cropped region independently to identify the presence or absence of safety equipment — including helmets, vests, gloves, and masks.
* **Metadata Re-attachment:** A second [`qtimetamux`](../plugin-reference/qtimetamux) instance re-attaches the PPE detection results to the original video stream, ensuring all detections are synchronized with the corresponding frame and person.
* **Hierarchical Metadata:** To preserve logical relationships across both model stages, the pipeline employs a **hierarchical metadata model** based on unique IDs and parent IDs — explicitly linking each PPE detection to its corresponding individual, enabling accurate per-person visualization, tracking, and downstream analytics.
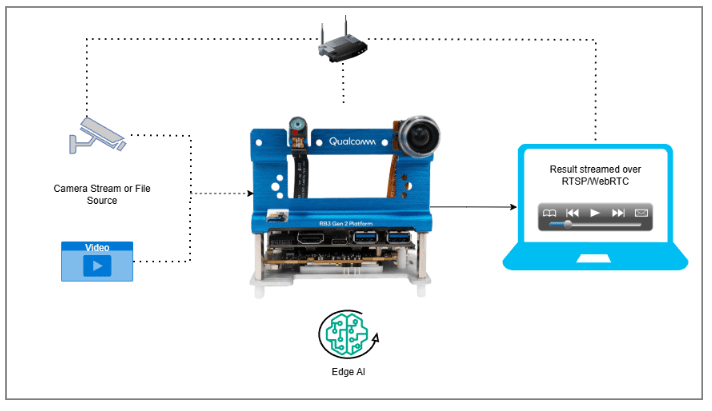
 ## Run application on device
### Setup Requirements
#### Hardware
## Run application on device
### Setup Requirements
#### Hardware
 | Component | Description |
| ------------------------ | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| **Edge Device** | RB3 Gen 2, IQ8, or IQ9 — Primary processing unit for AI inference and video composition. |
| **Camera Source** | IP/RTSP camera, ISP (on-device) camera, or USB camera. A local file source may be substituted if no physical camera is available. |
| **HDMI Display Monitor** | Connected to the edge device for rendering and visualizing pipeline output. |
| **PoE Switch** | Powers IP/RTSP cameras and provides network connectivity over a single Ethernet cable per camera. (Required for IP/RTSP camera setups only.) |
| **Local Network** | Ensures the edge device, RTSP camera, and host machine are reachable on the same network. (Required when using RTSP camera input or streaming results via RTSP or WebRTC.) |
#### Software
**Flash your Qualcomm Edge device** by following the device setup and flashing instructions [here](../installation)
**Once your device is ready**, follow the instructions below to set up the PPE AI Pipeline:
##### AI Model and config files
| File | Download | Save as |
| --------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------ | --------------------------------- |
| Person Foot Detection model | [Qualcomm AI Hub — FootTrackNet](https://aihub.qualcomm.com/models/foot_track_net) | `foot_track_net_quantized.tflite` |
| PPE Detection model | [Qualcomm AI Hub — GearGuardNet](https://aihub.qualcomm.com/models/gear_guard_net) | `gear_guard_net.tflite` |
| Foot track labels |
| Component | Description |
| ------------------------ | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| **Edge Device** | RB3 Gen 2, IQ8, or IQ9 — Primary processing unit for AI inference and video composition. |
| **Camera Source** | IP/RTSP camera, ISP (on-device) camera, or USB camera. A local file source may be substituted if no physical camera is available. |
| **HDMI Display Monitor** | Connected to the edge device for rendering and visualizing pipeline output. |
| **PoE Switch** | Powers IP/RTSP cameras and provides network connectivity over a single Ethernet cable per camera. (Required for IP/RTSP camera setups only.) |
| **Local Network** | Ensures the edge device, RTSP camera, and host machine are reachable on the same network. (Required when using RTSP camera input or streaming results via RTSP or WebRTC.) |
#### Software
**Flash your Qualcomm Edge device** by following the device setup and flashing instructions [here](../installation)
**Once your device is ready**, follow the instructions below to set up the PPE AI Pipeline:
##### AI Model and config files
| File | Download | Save as |
| --------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------ | --------------------------------- |
| Person Foot Detection model | [Qualcomm AI Hub — FootTrackNet](https://aihub.qualcomm.com/models/foot_track_net) | `foot_track_net_quantized.tflite` |
| PPE Detection model | [Qualcomm AI Hub — GearGuardNet](https://aihub.qualcomm.com/models/gear_guard_net) | `gear_guard_net.tflite` |
| Foot track labels | 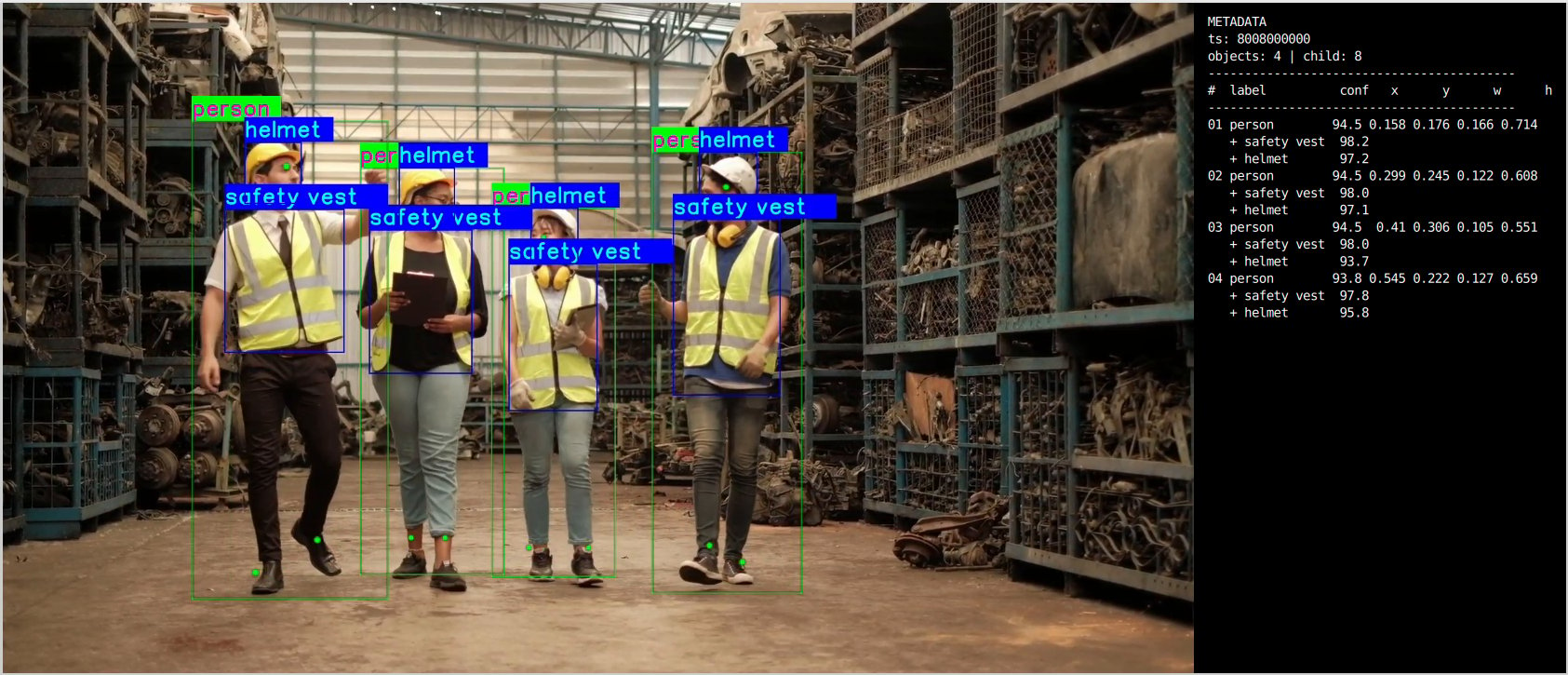 The pipeline generates structured JSON metadata in the following format:
```json theme={null}
{
"object_detection": [
{
"label": "person",
"confidence": 76.62,
"color": 16711935,
"rectangle": {
"x": 0.58,
"y": 0.05,
"width": 0.28,
"height": 0.90
},
"landmarks": {
"nose": {
"x": 0.71,
"y": 0.21
}
},
"object_detection": [
{
"label": "helmet",
"confidence": 97.79,
"color": 65535,
"rectangle": {
"x": 0.64,
"y": 0.05,
"width": 0.13,
"height": 0.29
}
}
]
}
],
"parameters": {
"timestamp": "11341424121"
}
}
```
## Command-Line Options
The pipeline generates structured JSON metadata in the following format:
```json theme={null}
{
"object_detection": [
{
"label": "person",
"confidence": 76.62,
"color": 16711935,
"rectangle": {
"x": 0.58,
"y": 0.05,
"width": 0.28,
"height": 0.90
},
"landmarks": {
"nose": {
"x": 0.71,
"y": 0.21
}
},
"object_detection": [
{
"label": "helmet",
"confidence": 97.79,
"color": 65535,
"rectangle": {
"x": 0.64,
"y": 0.05,
"width": 0.13,
"height": 0.29
}
}
]
}
],
"parameters": {
"timestamp": "11341424121"
}
}
```
## Command-Line Options